Анализ спроса в поисковых системах
Составление семантического ядра. Семантическое ядро запросов сайта – это набор запросов, которые довольно часто используют при поиске информации, имеющейся на сайте или близкой к ней по теме.
Разыскивая информацию, пользователи редко применяют научные формулировки, и поэтому нельзя заранее предсказать, как будет сформулирован их запрос. Для того чтобы проводить оптимизацию сайта для поисковых машин, а также понять, какими словами пользователи обозначают свою потребность (это можно использовать в рекламе), необходимо найти соответствие между темой сайта и набором формулировок запросов. Этот набор и является семантическим ядром запросов.
При составлении ядра запросов принимают во внимание ряд факторов:
♦ Учитывается смысл запроса, а не его форма, так как поисковая фраза, даже содержащая правильные слова, может быть нецелевой (например, запросом «телефоны Москвы» ищут, очевидно, справочник телефонов, и для продажи телефонов он не годится). Ориентация на смысл требует ручного труда, что делает составление семантического ядра очень трудоемким.
♦ Учитываются точные формулировки запросов. Грамотный подход к формированию ядра требует учета точных формулировок, потому что современные поисковые системы выдают разные результаты даже при перестановке слов в запросе, не говоря уже о добавлении уточняющих слов. Даже если сайт будет на первом месте по запросу «мобильные телефоны», это не значит, что он попадет в первую сотню по запросу «мобильные телефоны Siemens», сколько бы раз слово «Siemens» не употреблялось на странице. Это еще одна причина, существенно усложняющая составление семантического ядра.
♦ Для включения в ядро запрос должен быть достаточно частотным, иначе он может оказаться случайным, а поскольку таких запросов очень много, время будет потрачено зря. Из этого правила есть два исключения. Первое – группа очень дорогих товаров, когда каждый случайный посетитель может принести большую прибыль. Второе – специальные методы раскрутки, когда группа низкочастотных запросов помещается на страницу в виде списка. В этом случае очень важно продумать содержание и внешний вид страницы, чтобы она не оттолкнула потенциального клиента и не испортила впечатления о компании.
♦ Учитывается многозначность запроса. Если пользователь сделал запрос «краски», неизвестно, хочет ли он узнать что-либо о лакокрасочных материалах или интересуется группой «Краски». Решение о включении запроса в ядро принимается на основании предположений о доле целевых посетителей среди тех, кто задал данный запрос.
♦ Исключаются маловероятные и слишком узкие запросы. Если на сайте предлагается широкий перечень товаров, исследование всех запросов становится нереальным. В таком случае при довольно большом спросе в исследуемой области из ядра исключаются недорогие товары, запрос по которым маловероятен (например, «клипса с держателем»).
В отличие от анализа посещаемости и поведения посетителей на сайте, семантическое ядро позволяет оценить внешний по отношению к сайту спрос, изучить потенциальную аудиторию, которая еще не пришла на сайт.
Где применяется семантическое ядро? Полученные формулировки запросов можно применять для следующих целей:
♦ оптимизации сайта для поисковых систем (запросы используются для формирования текста страниц и ссылок);
♦ контекстной рекламы (ключевые слова для показа объявлений выбирают среди ядра запросов, эти же поисковые фразы включают в текст объявлений);
♦ обычной рекламы (если реклама содержит текст или слоган, желательно, чтобы он включал самую частотную поисковую фразу из ядра, подходящую по теме).
Методика формирования семантического ядра. Для получения семантического ядра запросов сайта выполняется ряд шагов.
♦ Анализ тематической области и текстов сайта с целью формирования начального списка запросов.
♦ Поиск возможных синонимов и однокоренных слов для всех ключевых терминов (для поисковых систем слова «компьютер» и «компьютерный» – два разных слова).
♦ Поиск сходных по смыслу запросов с помощью инструмента «Рамблер-Ассоциации».
♦ Поиск сопутствующих терминов, которые употребляются только в контексте целевой тематики с помощью инструмента «Яндекс. Директ». Например, запрос «3310» без слова «nokia» составляет примерно 12 % от частоты запроса «nokia 3310», причем 90 % вторичных поисковых запросов[1] относятся именно к телефону «Nokia 3310».
♦ Выявление терминов, которые используются как на русском, так и на английском языке.
♦ Анализ популярных запросов с целью выявления вариантов транслитерации (например, «сименс» и «сиеменс»), жаргонных названий («мобильный телефон» и «мобила»), орфографических ошибок (ericsson и ericson).
♦ Анализ частоты выявленных запросов с помощью «Яндекс. Директа».
♦ Исключение из списка нецелевых, редких, а также многозначных запросов. Для определения того, является ли запрос целевым, применяются человеческий интеллект, а также «Яндекс. Директ» (оценивается доля целевых вторичных поисковых запросов) и «Рамблер-Ассоциации» (оценивается доля целевых запросов среди тех, что связаны с данным).
Использование статистики «Яндекса» для составления семантического ядра допустимо, потому что структура пользовательского спроса в различных поисковых системах различается незначительно, что позволяет экстраполировать полученные результаты на всю русскоязычную часть Интернета. Согласно ряду оценок, полученных на основании статистики поисковых систем и счетчиков, доля «Яндекса» в поисковом спросе Рунета составляет около 50 %. Чтобы вычислить объем спроса в Рунете, следует данные, получаемые с помощью «Яндекс. Директа», умножать на коэффициент 2.
Порог частоты, после преодоления которого запрос не включается список, задается индивидуально для каждой темы. Чем больше в ней частотных запросов, тем выше порог. Редкие запросы на данном этапе избыточны, но как только будет исчерпан резерв в виде популярных запросов, для дополнительного увеличения поискового трафика можно будет охватить редкие запросы.
Классификация запросов. Запросы можно классифицировать по-разному. Здесь приведена одна из возможных классификаций – на три категории по типу искомой информации.
♦ Потребности посетителей. Данная группа запросов характеризует выраженную пользователем потребность, которую может удовлетворить товар или услуга компании, либо ситуацию, в которой могут понадобиться ее товары или услуги. Например, запрос «защита от скачков напряжения» не называет товар прямо, но подразумевает потребность, которую могут удовлетворить UPS, предлагаемые компанией.
♦ Товары и группы товаров, предлагаемые компанией. Это наиболее интересные запросы, так как их задает целевая аудитория, готовая к покупке.
♦ Бренды и торговые марки. В данной группе запросов приводятся поисковые фразы, включающие названия компаний, производящих предлагаемые товары, их торговые марки, а также запросы о самой компании.
В каждой из категорий имеет смысл выделить несколько групп запросов.
♦ Коммерческие запросы. Это самый лучший вариант – спрашивают о конкретном товаре, предлагаемом компанией.
♦ Некоммерческий (информационный) спрос. Типичный пример: только 0,05 % пользователей, задавших запрос «мелодии для мобильных телефонов», хотят купить мелодии, остальных интересует бесплатная загрузка. В то же время все они имеют мобильные телефоны, то есть могут быть потенциальными клиентами, покупая аксессуары для телефонов. Поэтому, если есть возможность недорогого привлечения посетителей по некоммерческим запросам, это стоит делать.
♦ Запросы, использующие жаргон или ошибки. Они могут появиться на страницах серьезного сайта только в завуалированном виде, поэтому для их использования необходимо придумывать специальные приемы.
♦ Менее целевые запросы. Сюда относятся слишком широкие, многозначные, а также не полностью подходящие по тем или иным причинам запросы. Например, некоторые запросы описывают потребности или товары, для удовлетворения которых предложение компании годится лишь частично. Поисковая фраза «мебель» подразумевает и детскую, и мягкую, и кухонную мебель, в то время как ваша компания может предлагать только офисную мебель. Такие запросы не являются полностью целевыми, и на них, как и на очень узкие запросы, следует ориентироваться, лишь когда будут исчерпаны остальные резервы.
Сбор ядра при помощи софта. KeyCollector.
Шаг 1. Скачиваем программы: http://www.key-collector.ru/buy.php.
Подробное описание софта находится по адресу http://www.key-collector.ru/about.php.
Шаг 2. Запускаем программу (рис. 5): 1 – главное меню, 2 – меню быстрого доступа, 3 – рабочая область, 4 – функциональные кнопки, 5, 6 – информационная область новостей и событий, 7 – строка состояния.

Рис. 5
Нажимаем кнопку Создать новый проект (рис. 6).

Рис. 6
Указываем регион (рис. 7).

Рис. 7
Шаг 3. Вводим запрос (рис. 8)
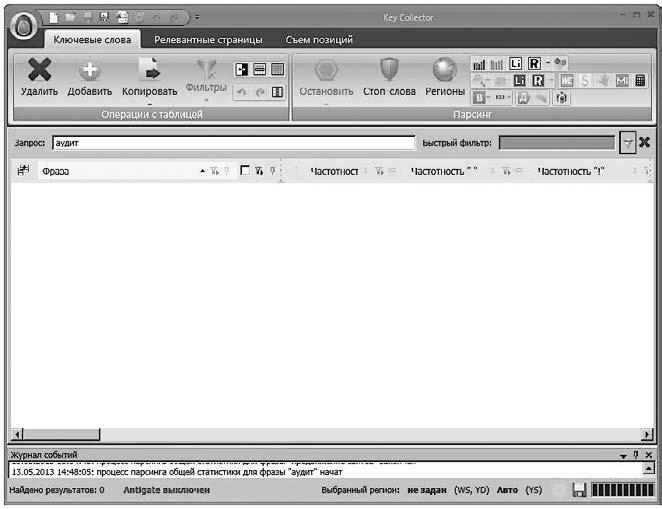
Рис. 8
Нажимаем клавишу Enter. Программа соберет запросы из Wordstat «Яндекса».
Шаг 4. Расширяем список при помощи поисковых подсказок (рис. 9).
ВАЖНО
При сборе запросов следует исключать запросы, которые являются разными словоформами одного и того же слова, иначе будет дан неверный прогноз трафика. Пример: «аудит», «аудита», «аудиту»; «кондиционер», «кондиционеры», «кондиционеров».
Шаг 5. Сбор частотностей запросов. Можно собрать как все виды частотностей, так и частотности в кавычках. Рекомендуется собирать частотности в кавычках.
Шаг 6. Сбор данных по сезонности. Нажимаем ссылку Сезонность. Программа определяет сезонность того или иного запроса (рис. 10).

Рис. 9

Рис. 10
Шаг 7. Анализ релевантных страниц. Нажимаем соответствующую кнопку и получаем данные по «Яндексу» или Google.
Шаг 8. Экспорт данных. Кнопка, которой он задается, не очень заметна (рис. 11). Данные экспортируются в формате Microsoft Excel 2007 (XLSX) или CSV.

Рис. 11
ВАЖНО
При сборе запросов можно воспользоваться кнопкой Собрать все (рис. 12). Она запускает глобальный процесс поиска информации.

Рис. 12
Поскольку парсинг по большому количеству запросов производится не быстро, разработчики предлагают любопытную особенность – проигрывание мелодии по окончании процесса.
Следующая деталь важна. Это антикапча. Программа поддерживается сервисом antigate.com, пользователю нужно зарегистрироваться на сайте и получить 32-символьный ключ (рис. 13).

Рис. 13
Этот ключ следует занести на специальную вкладку панели настроек (рис. 14).

Рис. 14
Полезна также поддержка сервисом SeoProxy – сбор данных с Yandex.Wordstat и с поисковой выдачи «Яндекса» можно будет производить без утомительной капчи.
Шаг 9. Очистка списка от мусорных запросов. Можно выполнять его из самой программы, но я делаю это в итоговом файле Excel.
Получаем ядро запросов с указанием частотности и сезонности и даже релевантными страницами по версии «Яндекса» и Google. Что делать, если запросов мало? Как вариант можно использовать «СловоДер» (http://seom.info/downloads/?download=Slovoder.exe).
Скачиваем программу, запускаем, вводим запрос (рис. 15).
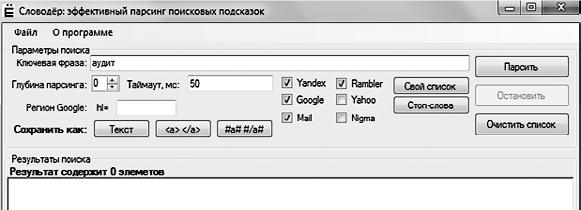
Рис. 15
Нажимаем кнопку Парсить. Получаем множество запросов для анализа (рис. 16).

Рис. 16
Тонкости сбора ядра запросов для интернет-магазинов. Запросы ядра для интернет-магазинов можно разделить на следующие группы.

Эти группы выстраиваются в четкую иерархию.
1. Общие запросы.
2. Запросы по категориям товара.
3. Запросы по брендам внутри категории.
4. Запросы по конкретным наименованиям товара.
Количество запросов в таком ядре зависит от количества товаров, которые продаются в интернет-магазине. Для его определения, как правило, количество товаров нужно умножать на 5. Если ассортимент интернет-магазина – 1000 товаров, то запросов только по карточкам товаров будет 4000–5000. Плюс запросы по брендам и категориям и общие.
Например, вам надо собрать ядро для интернет-магазина, который торгует 5 категориями товара, в каждой из которых по 5 брендов. Это значит, что на выходе получится минимум 25 групп запросов – 5 категорий · 5 брендов.