Глава 2. Обучение нейросетей с прямым распространением сигнала
Проблема фастфуда
Мы начинаем понимать, как решать некоторые интересные задачи с помощью глубокого обучения, но остается важный вопрос: как определить, какими должны быть векторы параметров (веса всех соединений нейросети)? Ответ прост: в ходе процесса, часто именуемого обучением (рис. 2.1). Мы демонстрируем нейросети множество обучающих примеров и последовательно модифицируем веса, чтобы минимизировать ошибки, которые уже были совершены. Продемонстрировав достаточное число примеров, мы ожидаем, что нейросеть будет эффективно решать поставленную задачу.

Рис. 2.1. Нейрон, который мы хотим обучить решать проблему фастфуда
Вернемся к примеру, который упоминали в предыдущей главе при обсуждении линейного нейрона. Итак: каждый день мы покупаем в ресторане быстрого обслуживания обед – бургеры, картошку и газировку, причем по несколько порций каждого наименования. Мы хотим предсказывать, сколько будет стоить обед, но ценников нет. Кассир сообщает только общую цену.
Мы хотим обучить один линейный нейрон решать эту задачу. Как?
Один из вариантов – разумно подбирать примеры для обучения. Для одного обеда купим один бургер, для второго – одну порцию картошки, для третьего – один стакан газировки. В целом разумный подбор примеров – хорошая идея. Многие исследования показывают, что, создав хорошую подборку данных для обучения, вы сможете заметно повысить эффективность нейросети. Но проблема использования только этого подхода в том, что в реальных ситуациях он редко приближает нас к решению. Например, при распознавании изображений аналога ему нет и решения мы не найдем.
Нам нужно найти вариант, который поможет решать задачу в общем случае. Допустим, у нас очень большой набор обучающих примеров. Это позволит нам вычислить, какие выходные значения выдаст нейросеть на i-м примере, при помощи простой формулы. Мы хотим обучить нейрон и подбираем оптимальные веса, чтобы свести к минимуму ошибки при распознавании примеров. Можно сказать, мы хотим свести к минимуму квадратичную ошибку во всех примерах, которые встретим. Формально, если мы знаем, что t(i) – верный ответ на i-й пример, а y(i) – значение, вычисленное нейросетью, мы хотим свести к минимуму значение функции потерь E:

Квадратичная ошибка равна 0, когда модель дает корректные предсказания для каждого обучающего примера. Более того, чем ближе E к 0, тем лучше модель. Наша цель – выбрать такой вектор параметров θ (значения всех весов в этой модели), чтобы E было как можно ближе к 0.
Вы, возможно, недоумеваете: зачем утруждать себя функцией потерь, если проблему легко решить с помощью системы уравнений. В конце концов, у нас есть наборы неизвестных (весов) и уравнений (одно для каждого примера). Это автоматически даст нам ошибку, равную 0, если обучающие примеры подобраны удачно.
Хорошее замечание, но, к сожалению, актуальное не для всех случаев. Мы применяем здесь линейный нейрон, но на практике они используются редко, ведь их способности к обучению ограничены. А когда мы начинаем использовать нелинейные нейроны – сигмоиду, tanh или усеченный линейный, о которых мы говорили в конце предыдущей главы, – мы не можем задать систему уравнений! Так что для обучения явно нужна стратегия получше[9].
Градиентный спуск
Визуализируем для упрощенного случая то, как свести к минимуму квадратичную ошибку по всем обучающим примерам. Допустим, у линейного нейрона есть только два входа (и соответственно только два веса – w1 и w2). Мы можем представить себе трехмерное пространство, в котором горизонтальные измерения соответствуют w1 и w2, а вертикальное – значению функции потерь E. В нем точки на горизонтальной поверхности сопоставлены разным значениям весов, а высота в них – допущенной ошибке. Если рассмотреть все ошибки для всех возможных весов, мы получим в этом трехмерном пространстве фигуру, напоминающую миску (рис. 2.2).

Рис. 2.2. Квадратичная поверхность ошибки для линейного нейрона
Эту поверхность удобно визуализировать как набор эллиптических контуров, где минимальная ошибка расположена в центре эллипсов. Тогда мы будем работать с двумерным пространством, где измерения соответствуют весам. Контуры сопоставлены значениям w1 и w2, которые дают одно и то же E. Чем ближе они друг к другу, тем круче уклон. Направление самого крутого уклона всегда перпендикулярно контурам. Его можно выразить в виде вектора, называемого градиентом.
Пора разработать высокоуровневую стратегию нахождения значений весов, которые сведут к минимуму функцию потерь. Допустим, мы случайным образом инициализируем веса сети, оказавшись где-то на горизонтальной поверхности. Оценив градиент в текущей позиции, мы можем найти направление самого крутого спуска и сделать шаг в нем. Теперь мы на новой позиции, которая ближе к минимуму, чем предыдущая. Мы проводим переоценку направления самого крутого спуска, взяв градиент, и делаем шаг в новом направлении. Как показано на рис. 2.3, следование этой стратегии со временем приведет нас к точке минимальной ошибки. Этот алгоритм известен как градиентный спуск, и мы будем использовать его для решения проблемы обучения отдельных нейронов и целых сетей[10].

Рис. 2.3. Визуализация поверхности ошибок как набора контуров
Дельта-правило и темп обучения
Прежде чем вывести точный алгоритм обучения фастфудного нейрона, поговорим о гиперпараметрах. Помимо весов, определенных в нашей нейросети, обучающим алгоритмам нужен ряд дополнительных параметров. Один из этих гиперпараметров – темп обучения.
На каждом шаге движения перпендикулярно контуру нам нужно решать, как далеко мы хотим зайти, прежде чем заново вычислять направление. Это расстояние зависит от крутизны поверхности. Почему? Чем ближе мы к минимуму, тем короче должны быть шаги. Мы понимаем, что близки к минимуму, поскольку поверхность намного более плоская и крутизну мы используем как индикатор степени близости к этому минимуму. Но если поверхность ошибки рыхлая, процесс может занять много времени. Поэтому часто стоит умножить градиент на масштабирующий коэффициент – темп обучения. Его выбор – сложная задача (рис. 2.4).
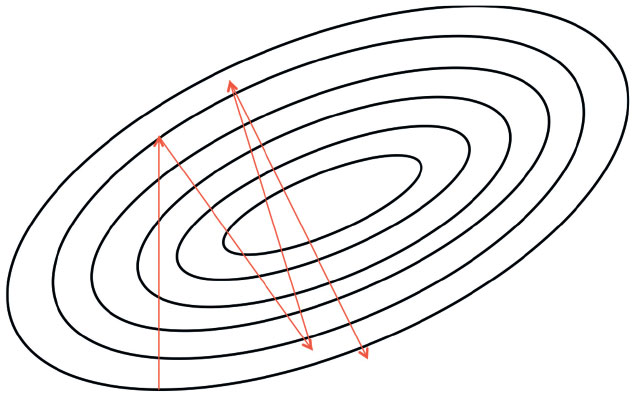
Рис. 2.4. Если темп обучения слишком велик, возникают проблемы со сходимостью
Как мы уже говорили, если он будет слишком мал, возможно, процесс займет слишком много времени. Но если темп будет слишком высоким, то кончится это, скорее всего, тем, что мы отклонимся от минимума. В главе 4 мы поговорим о методах оптимизации, в которых используются адаптивные темпы обучения для автоматизации выбора.
Теперь мы готовы вывести дельта-правило для обучения линейного нейрона. Чтобы вычислить, как изменять каждый вес, мы оцениваем градиент: по сути, частную производную функции потерь по каждому из весов. Иными словами, нам нужен такой результат:

Применяя этот метод изменения весов при каждой итерации, мы получаем возможность использовать градиентный спуск.
Градиентный спуск с сигмоидными нейронами
В этом и следующем разделах мы будем говорить об обучении нейронов и нейросетей, использующих нелинейности. В качестве образца возьмем сигмоидный нейрон, а расчеты для других нелинейных нейронов оставим читателям как упражнение. Для простоты предположим, что нейроны не используют смещение, хотя наш анализ вполне можно распространить и на такой случай. Допустим, смещение – вес входа, на который всегда подается 1.
Напомним механизм, с помощью которого логистические нейроны вычисляют выходные значения на основе входных:
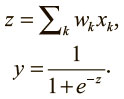
Нейрон определяет взвешенную сумму входящих значений – логит z. Затем он передает этот логит в нелинейную функцию для вычисления выходного значения y. К счастью для нас, эти функции имеют очень красивые производные, что значительно упрощает дело! Для обучения нужно вычислить градиент функции потерь по весам. Возьмем производную логита по входным значениям и весам:
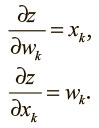
Кроме того, как ни удивительно, производная выходного значения по логиту проста, если выразить ее через выходное значение:

Теперь можно использовать правило дифференцирования сложной функции, чтобы вычислить производную выходного значения по каждому из весов:

Объединяя полученные результаты, мы можем вычислить производную функции потерь по каждому весу:

Итоговое правило изменения весов будет выглядеть так:

Как вы видите, новое правило очень похоже на дельта-правило, за исключением дополнительных множителей для учета логистического компонента сигмоидного нейрона.
Алгоритм обратного распространения ошибок
Теперь мы готовы приступить к проблеме обучения многослойных нейросетей, а не только одиночных нейронов. Обратимся к подходу обратного распространения ошибок, предложенному Дэвидом Румельхартом, Джеффри Хинтоном и Рональдом Уильямсом в 1986 году[11]. В чем основная идея? Мы не знаем, что делают скрытые нейроны, но можем вычислить, насколько быстро меняется ошибка, если мы вносим корректировки в эти процессы. На основе этого мы способны определить, как быстро трансформируется ошибка, если изменить вес конкретного соединения. По сути, мы пытаемся найти наибольший уклон! Единственная сложность в том, что приходится работать в пространстве с очень большим числом измерений. Начнем с вычисления производных функции потерь по одному обучающему примеру.
Каждый скрытый нейрон может влиять на многие выходные нейроны. Нам нужно учесть несколько эффектов ошибки, чтобы получить нужную информацию. В качестве стратегии выберем динамическое программирование. Получив производные функций потерь для одного слоя скрытых нейронов, мы применим их для вычисления производных функций потерь на выходе более низкого слоя. Когда мы найдем такие производные на выходе из скрытых нейронов, несложно будет получить производные функций потерь для весов входов в скрытый нейрон. Для упрощения введем дополнительные обозначения (рис. 2.5).

Рис. 2.5. Справочная диаграмма для вывода алгоритма обратного распространения ошибок
Нижний индекс будет обозначать слой нейронов; символ y – как обычно, выходное значение нейрона, а z – логит нейрона. Начнем с базового случая проблемы динамического программирования: вычислим производные функции потерь на выходном слое (output).

Теперь сделаем индуктивный шаг. Предположим, у нас есть производные функции потерь для слоя j. Мы собираемся вычислить производные функции потерь для более низкого слоя i. Для этого необходима информация о том, как выходные данные нейрона в слое i воздействуют на логиты всех нейронов в слое j. Вот как это сделать, используя то, что частная производная логита по входящим значениям более низкого слоя – это вес соединения wij:

Далее мы видим следующее:
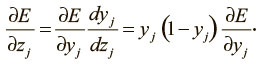
Сведя эти факты воедино, мы можем выразить производные функций потерь слоя i через производные функций потерь слоя j:

Пройдя все стадии динамического программирования и заполнив таблицу всеми частными производными (функций потерь по выходным значениям скрытых нейронов), мы можем определить, как ошибка меняется по отношению к весам. Это даст нам представление о том, как корректировать веса после каждого обучающего примера:
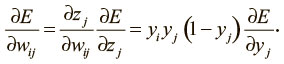
Наконец, чтобы завершить алгоритм, как и раньше, мы суммируем частные производные по всем примерам в нашем наборе данных (dataset). Это дает нам следующую формулу изменения:

На этом описание алгоритма обратного распространения ошибок закончено!
Стохастический и мини-пакетный градиентный спуск
В алгоритмах, описанных в предыдущем разделе, мы использовали так называемый пакетный градиентный спуск. Идея в том, что мы при помощи всего набора данных вычисляем поверхность ошибки, а затем следуем градиенту, определяем самый крутой уклон и движемся в этом направлении. Для поверхности простой квадратичной ошибки это неплохой вариант. Но в большинстве случаев поверхность гораздо сложнее. Для примера рассмотрим рис. 2.6.

Рис. 2.6. Пакетный градиентный спуск чувствителен к седловым точкам, что может привести к преждевременному схождению
У нас только один вес, и мы используем случайную инициализацию и пакетный градиентный спуск для поиска его оптимального значения. Но поверхность ошибки имеет плоскую область (известную в пространствах с большим числом измерений как седловая точка). Если нам не повезет, то при пакетном градиентном спуске мы можем застрять в ней.
Другой возможный подход – стохастический градиентный спуск (СГС). При каждой итерации поверхность ошибки оценивается только для одного примера. Этот подход проиллюстрирован на рис. 2.7, где поверхность ошибки не единая статичная, а динамическая. Спуск по ней существенно улучшает нашу способность выходить из плоских областей.

Рис. 2.7. Стохастическая поверхность ошибки варьирует по отношению к пакетной, что позволяет решить проблему седловых точек
Основной недостаток стохастического градиентного спуска в том, что рассмотрение ошибки для одного примера может оказаться недостаточным приближением поверхности ошибки.
Это, в свою очередь, приводит к тому, что спуск займет слишком много времени. Один из способов решения проблемы – использование мини-пакетного градиентного спуска. При каждой итерации мы вычисляем поверхность ошибки по некой выборке из общего набора данных (а не одному примеру). Это и есть мини-пакет (minibatch), и его размер, как и темп обучения, – гиперпараметр. Мини-пакеты уравновешивают эффективность пакетного градиентного спуска и способность избегать локальных минимумов, которую предоставляет стохастический градиентный спуск. В контексте обратного распространения ошибок изменение весов выглядит так:

Это идентично тому, что мы вывели в предыдущем разделе. Но вместо того чтобы суммировать все примеры в наборе данных, мы обобщаем все примеры из текущего мини-пакета.
Переобучение и наборы данных для тестирования и проверки
Одна из главных проблем искусственных нейросетей – чрезвычайная сложность моделей. Рассмотрим сеть, которая получает данные от изображения из базы данных MNIST (28×28 пикселов), передает их в два скрытых слоя по 30 нейронов, а затем в слой с мягким максимумом из 10 нейронов. Общее число ее параметров составляет около 25 тысяч. Это может привести к серьезным проблемам. Чтобы понять почему, рассмотрим еще один упрощенный пример (рис. 2.8).

Рис. 2.8. Две модели, которыми может быть описан наш набор данных: линейная и многочлен 12-й степени
У нас есть ряд точек на плоской поверхности, задача – найти кривую, которая наилучшим образом опишет этот набор данных (то есть позволит предсказывать координату y новой точки, зная ее координату x). Используя эти данные, мы обучаем две модели: линейную и многочлен 12-й степени. Какой кривой стоит доверять? Той, которая не попадает почти ни в один обучающий пример? Или сложной, которая проходит через все точки из набора? Кажется, можно доверять линейному варианту, ведь он кажется более естественным. Но на всякий случай добавим данных в наш набор! Результат показан на рис. 2.9.

Рис. 2.9. Оценка модели на основе новых данных показывает, что линейная модель работает гораздо лучше, чем многочлен 12-й степени
Вывод очевиден: линейная модель не только субъективно, но и количественно лучше (по показателю квадратичной ошибки). Но это ведет к очень интересному выводу по поводу усвоения информации и оценки моделей машинного обучения. Строя очень сложную модель, легко полностью подогнать ее к обучающему набору данных. Ведь мы даем ей достаточно степеней свободы для искажения, чтобы вписаться в имеющиеся значения. Но когда мы оцениваем такую модель на новых данных, она работает очень плохо, то есть слабо обобщает. Это явление называется переобучением. И это одна из главных сложностей, с которыми вынужден иметь дело инженер по машинному обучению. Нейросети имеют множество слоев с большим числом нейронов, и в области глубокого обучения эта проблема еще значительнее. Количество соединений в моделях составляет миллионы. В результате переобучение – обычное дело (что неудивительно).
Рассмотрим, как это работает в нейросети. Допустим, у нас есть сеть с двумя входными значениями, выходной слой с двумя нейронами с функцией мягкого максимума и скрытый слой с 3, 6 или 20 нейронами. Мы обучаем эти нейросети при помощи мини-пакетного градиентного спуска (размер мини-пакета 10); результаты, визуализированные в ConvNetJS, показаны на рис. 2.10[12].

Рис. 2.10. Визуализация нейросетей с 3, 6 и 20 нейронами (в таком порядке) в скрытом слое
Уже из этих изображений очевидно, что с увеличением числа соединений нейросети усиливается тенденция к переобучению. Усугубляется она и с углублением нейросетей. Результаты показаны на рис. 2.11, где используются сети с 1, 2 или 4 скрытыми слоями, в каждом из которых по 3 нейрона.

Рис. 2.11. Визуализация нейросетей с 1, 2 и 4 скрытыми слоями (в таком порядке), по 3 нейрона в каждой
Отсюда следуют три основных вывода. Во-первых, инженер по машинному обучению всегда вынужден искать компромисс между переобучением и сложностью модели. Если модель недостаточно сложна, она может оказаться недостаточно мощной для извлечения всей полезной информации, необходимой для решения задачи. Но если она слишком сложна (особенно когда у нас есть ограниченный набор данных), высока вероятность, что понадобится переобучение. Глубокое обучение связано с решением очень сложных задач при помощи сложных моделей, поэтому необходимо принимать дополнительные меры против возможного переобучения. О многих из них мы будем говорить в этой главе, а также в следующих.
Во-вторых, неприемлемо оценивать модель на основе данных, с помощью которых мы ее обучали. Так, пример на рис. 2.8 дает ошибочное представление о том, что модель многочлена 12-й степени лучше линейной. В результате мы почти никогда не обучаем модель на полном наборе данных. Как показано на рис. 2.12, мы делим данные на наборы для обучения и тестирования.

Рис. 2.12. Мы часто делим данные на несовпадающие наборы для обучения и тестирования, чтобы дать справедливую оценку нашей модели
Это позволяет дать справедливую оценку модели, непосредственно измерив ее способность к обобщению на новых данных, с которыми она еще не знакома. В реальном мире большие массивы данных встречаются редко, и можно подумать, что ошибкой было бы не использовать в обучающем процессе все данные, имеющиеся в нашем распоряжении. Порой очень хочется заново использовать обучающие данные для тестирования или срезать углы, собирая тестовый набор данных. Но будьте осторожны: если последний составлен недостаточно внимательно, мы не сможем сделать значимых выводов по поводу нашей модели.
В-третьих, вероятно, наступит момент, когда модель вместо исследования полезных признаков начнет переобучаться. Чтобы этого избежать, нужно предусмотреть немедленное завершение процесса при переобучении, что позволит избежать некорректных обобщений. Для этого тренировочный процесс делится на эпохи. Эпоха – одна итерация обучения на всем наборе. Если у нас есть набор размера d и мы проводим мини-пакетный градиентный спуск с размером пакета b, эпоха будет эквивалентна d/b обновлений. В конце каждой эпохи нужно измерить, насколько успешно наша модель обобщает. Для этого мы вводим дополнительный проверочный набор, показанный на рис. 2.13. В конце эпохи он покажет нам, как модель будет работать с еще не известными ей данными. Если точность на обучающем наборе будет возрастать, а для проверочного останется прежней или ухудшится, пора прекратить процесс: началось переобучение.
Рис. 2.13. В глубоком обучении часто используется проверочный набор, препятствующий переобучению