Cloudera QuickStart VM

Для начала работы нам нужно скачать виртуальную машину Cloudera, позволяющую ознакомиться со стеком Cloudera Hadoop.

После скачивания и распаковки архива, запустим виртуальную машину.

Для этого в VirtualBox импортируем скачанную конфигурацию ovf.

После запуска виртуальной машины Cloudera QuickStart вы увидите рабочий стол и открытый браузер.
И если вы посмотрите на этот браузер, вы увидите, что здесь представлено несколько разных сервисов Cloudera.
Здесь есть Hue, Hadoop, HBase, Impala, Spark, и т. д.
Это все приложения стека Cloudera Hadoop.
Здесь браузер выступает как клиент, для доступа к этим сервисам, запущенным на виртуальной машине, для доступа с помощью URL адреса.
И давайте пройдемся по ним и узнаем, что они нам могут предоставить.

Откроем вкладку Overview NameNode Hadoop.
Здесь мы видим обзор нашего стека Hadoop.
Мы можем видеть, когда произошла инициализация этого стека.
И этот обзор дает нам полную сводку по всем конфигурациям, количеству файлов и т. д.

Давайте откроем вкладку Datanodes.
Этот сервис позволяет посмотреть на все имеющиеся у нас Datanodes.
Напомним, что кластер HDFS состоит из одного NameNode, главного сервера, который управляет пространством имен файловой системы и регулирует доступ клиентов к файлам.
И существуют узлы данных Datanodes, обычно по одному на узел кластера, которые управляют хранилищем, подключенным к узлам.

Откроем вкладку RegionServer HBase/
HBase – это столбцовое хранилище данных, которое хранит неструктурированные данные в файловой системе Hadoop.
Здесь показывается количество запросов, которые делаются для чтения и записи в базу данных HBase.
И мы можем видеть все вызовы и задачи, которые были переданы в базу данных.

Impala позволяет нам отправлять высокопроизводительные SQL-подобные запросы к данным, хранящимся в HDFS.
И здесь мы можем посмотреть последние 25 выполненных запросов, мы можем посмотреть на запросы, которые происходят прямо сейчас, мы можем посмотреть на местоположения и фрагменты, к которым были отправлены эти запросы.
Далее, давайте откроем вкладку Oozie.
Здесь мы можем увидеть количество отправленных заданий, когда они были запущены, и т. д.

Теперь, давайте вернемся к исходной веб-странице, странице приветствия, и нажмем Start Tutorial.
И этот урок предложит нам введение в стек Cloudera.

На этой странице говорится, что в этом уроке представлены примеры в контексте созданной корпорации под названием DataCo.

И вопрос первого упражнения – какие продукты любят покупать клиенты корпорации?
Чтобы ответить на этот вопрос, вы можете посмотреть на данные транзакций, которые должны указать, что клиенты покупают.
Вероятно, вы можете это сделать в обычной реляционной базе данных.
Но преимущество платформы Cloudera заключается в том, что вы можете делать это в большем масштабе при меньших затратах.
Здесь сбоку есть информация о Scoop.
Это инструмент, который использует Map Reduce для эффективной передачи данных между кластером Hadoop и реляционной базой данных.
Он работает путем порождения нескольких узлов данных, чтобы загружать различные части данных параллельно.
И по окончании, каждый фрагмент данных будет реплицирован для обеспечения доступности и распределения по кластеру, чтобы вы могли параллельно обрабатывать данные в кластере.
И в платформу Cloudera включены две версии Sqoop.
Sqoop1 – это толстый клиент.
И Scoop2 состоит из центрального сервера и тонкого клиента, который вы можете использовать для подключения к серверу.
Ниже, вы можете посмотреть структуру таблицы данных.
Чтобы проанализировать данные транзакций на платформе Cloudera, нам нужно ввести их в распределенную файловую систему Hadoop (HDFS).
И нам нужен инструмент, который легко переносит структурированные данные из реляционной базы данных в HDFS, сохраняя при этом структуру.
И Apache Sqoop является этим инструментом.
С помощью Sqoop мы можем автоматически загружать данные из MySQL в HDFS, сохраняя при этом структуру.

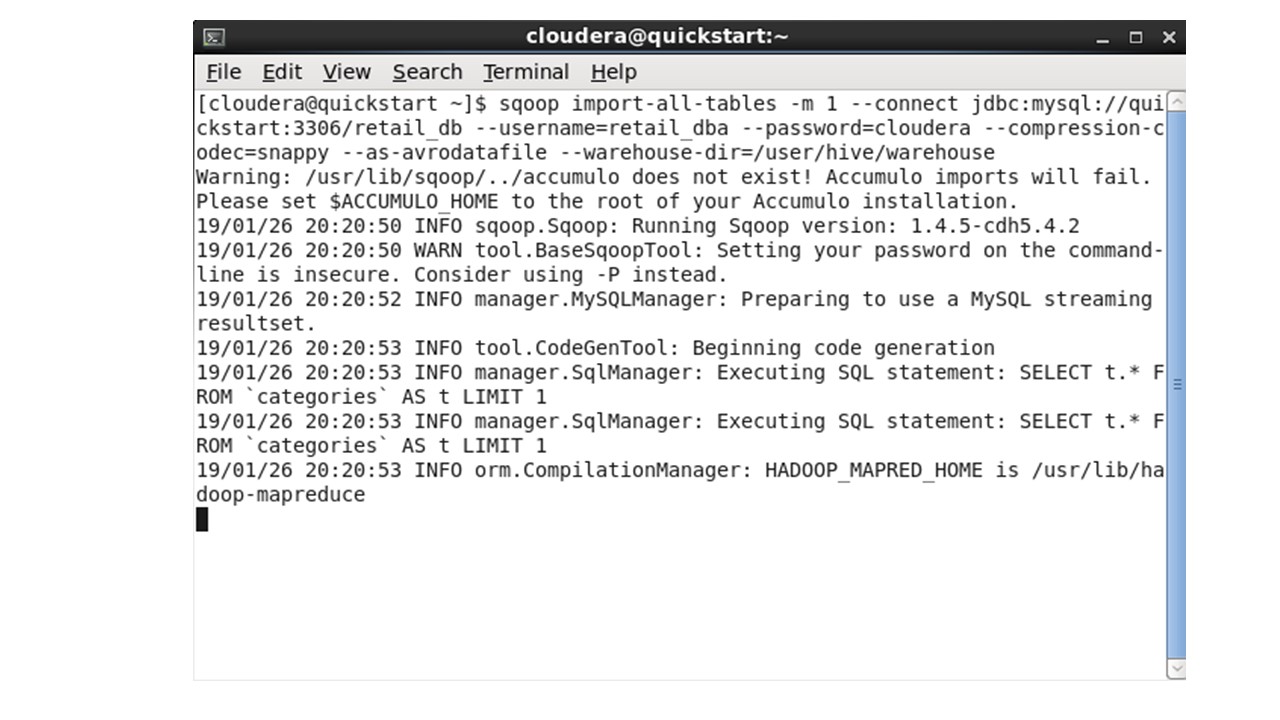
Вверху в меню откроем терминал, и запустим это задание Sqoop.
Эта команда запускает задания MapReduce для экспорта данных из базы данных MySQL и размещения этих файлов экспорта в формате Avro в HDFS.
Эта команда также создает схему Avro, чтобы мы могли легко загрузить таблицы Hive для последующего использования в Impala.
Impala – это механизм аналитических запросов.
И Avro – это формат файлов, оптимизированный для Hadoop.

Таким образом, мы скопируем код и запустим команду в терминале.
После выполнения задания, чтобы подтвердить, что данные существуют в HDFS, мы скопируем следующие команды в терминал.
Которые покажут папку для каждой из таблиц и покажут файлы в папке категорий.

Инструмент Sqoop также должен был создать файлы схемы для этих данных.
И эта команда должна показать avsc схемы для шести таблиц базы данных.
Таким образом, схемы и данные хранятся в отдельных файлах.
И схема применяется к данным, только когда данные запрашиваются.
И это то, что мы называем схемой на чтение.
Это дает гибкость при запросе данных с помощью SQL.
И это отличие от традиционных баз данных, которые требуют, чтобы у вас была четкая схема, прежде чем вводить в базу какие-либо данные. Здесь мы вводим данные, а уже потом применяем к ним схему.

Теперь, так как мы хотим использовать Apache Hive, нам понадобятся файлы схем.
Поэтому с помощью этой команду скопируем их в HDFS, где Hive может легко получить к ним доступ.
Вы могли заметить, что мы импортировали данные в каталоги Hive.
И Hive и Impala читают данные из файла в HDFS, и они даже обмениваются метаданными о таблицах.
Отличие состоит в том, что Hive выполняет запросы, компилируя их в задания MapReduce.
В то время как Impala является механизмом системы параллельных запросов, которые считывают данные непосредственно из самой файловой системы, в более быстром и интерактивном режиме.
Таким образом, мы загрузили данные с помощью Sqoop в HTFS, преобразовав их в формат Avro, и импортировали файлы схем, для их использования при запросе этих данных.
И теперь, давайте перейдем к следующему упражнению.

Здесь мы будем использовать Hue, приложение Impala, для создания метаданных для наших таблиц.
Мы создадим эти метаданные, а затем сделаем запрос к нашей таблице используя Hue.
Hue предоставляет веб-интерфейс, который доступен на порту 8888.

Чтобы войти в Hue, введем сloudera в качестве имени пользователя и пароля.

Далее в меню Query Editors откроем Impala.

Скопируем и вставим код, который создаст таблицы.

И обновим данные в левой колонке, чтобы увидеть созданные таблицы.

Теперь, когда данные доступны для запросов, мы можем ответить на вопрос, какие продукты покупают клиенты.
Для этого скопируем и вставим SQL запросы для расчета общей выручки по продукту и отображения 10 лучших продуктов, приносящих доход.

После выполнения, в Hue, мы увидим результаты запроса.

Таким образом мы узнали, как создавать и запрашивать таблицы с помощью Impala.
Теперь, давайте перейдем к следующему уроку.
И далее мы должны посмотреть, какие преимущества дает стек Cloudera по сравнению с традиционными системами.

Здесь мы попытаемся соотнести структурированные данные с неструктурированными данными и сможем ответить на вопрос – являются ли наиболее просматриваемые товары наиболее продаваемыми.