Неделя 1. Простой шифр подстановки
Ну что ж, начать, пожалуй, нужно с самого простого. Давай разберёмся, что такое шифр.
Шифрование – это метод сокрытия и раскрытия смысла посланий. Сейчас ты читаешь этот текст и понимаешь его смысл. А если бы я не хотел, чтобы любой человек мог понять то, что здесь написано, я бы использовал шифр – например, так: «14 16 13 16 05 06 24 25 20 16 17 16 17 18 16 02 16 03 01 13». Никто кроме меня и тех, кого я посвящу в метод шифровки этого сообщения, не сможет его расшифровать. Другими словами, шифр (или шифровка, или зашифрованное сообщение) – это открытый текст, смысл которого скрыт.
Что значит «открытый текст»? Это такой текст, про который понятно, что он есть. Он доступен не только отправителю (автору) и получателю, но и любому другому человеку. Обычно сообщения – как шифрованные, так и нет, – являются открытыми. К примеру, текст этой книги – открытый. Но есть и закрытые тексты, то есть такие, о существовании которых доподлинно знают только отправитель и получатель. Остальные люди могут разве что догадываться о его существовании. О закрытых сообщениях мы поговорим чуть позже.
А что же значит «скрытый смысл»? Это значит, что даже если сам текст открыт, понять его могут только отправитель и получатель. Остальные могут попытаться его понять, а при должной сноровке и знаниях раскрыть скрытый смысл, расшифровав послание. А вот обычный, нешифрованный текст имеет открытый смысл – он понятен всем, кто владеет языком, на котором текст написан, и обладает достаточным уровнем знаний для понимания.
Итак, представь себе способ шифрования, когда каждая буква текста заменяется каким-либо символом или числом. Самый простой способ заключается в использовании вместо букв их порядковых номеров. В русском алфавите 33 буквы, так что будут понадобятся числа от 1 до 33. Например, вот так можно зашифровать слово «ШИФР»: 26 10 22 18.
Само собой, это совсем негодный способ шифрования. Боюсь, такой шифр взломает даже тот, кто не читал эту книгу. По крайней мере, большинству людей первым делом придёт в голову попробовать этот способ расшифровки.
Буквы можно заменять и другими буквами. Например, можно воспользоваться правилом «+3»: чтобы зашифровать букву, необходимо взять её номер в алфавите, прибавить к нему «3», а затем использовать букву с полученным порядковым номером. Чтобы зашифровать буквы из конца алфавита, нужно вернуться в начало алфавита, как бы замкнув круг. Это правило позволит зашифровать слово «ШИФР» так: ЫЛЧУ.

Гай Юлий Цезарь. Древнеримский государственный и политический деятель, полководец, писатель. Для передачи секретных сообщений из штаба в войска впервые использовал простой шифр подстановки, сегодня известный как «шифр Цезаря».
Это так называемый «шифр Цезаря». Именно в таком виде Юлий Цезарь использовал его для секретной переписки со своими командирами легионов. Да, в те далёкие времена этот шифр обеспечивал секретность. Но теперь и он не очень хорошо сохраняет тайну, поскольку те, кто хоть немного знает о криптоанализе, мгновенно взломают его (скоро и ты будешь таким человеком).
Наконец, буквы можно заменять на какие-нибудь экзотические значки; их даже можно выдумать самостоятельно. Здесь открывается широкий простор для фантазии. Например, то же слово «ШИФР» в этом случае можно написать бесконечным количеством способов:  и т. д. Придумать можно всё что угодно. Однако и в этом случае ни вид символов, ни их сложность не являются защитой – такой шифр можно взломать так же легко, как и в предыдущем варианте.
и т. д. Придумать можно всё что угодно. Однако и в этом случае ни вид символов, ни их сложность не являются защитой – такой шифр можно взломать так же легко, как и в предыдущем варианте.
Честно говоря, я бы вообще не называл это шифрованием. С точки зрения математика и программиста это просто смена кодировки. Мы просто используем другие обозначения для тех же самых букв. Это ни на что не влияет с точки зрения защиты сообщения. Подумай хорошенько: если букву «А» всегда заменять одним и тем же другим символом, букву «Б» – каким-то другим символом и так далее, то это отпугнёт только совсем неподготовленных людей, да и то – после первого испуга каждый сможет разобраться, в чём тут дело.
Другими словами, можно вывести такое правило:
Если заменить буквы на какие-либо иные символы, то секретность сообщения не изменится.
Давай посмотрим, как можно взломать такой шифр. Для этого есть несколько методов:
1. Частотный анализ символов. Что обозначает этот термин? Одни и те же буквы, какими бы значками они ни обозначались, всегда используются в одном и том же языке с одинаковой частотой. Сейчас ты читаешь этот текст (на русском языке); можно подсчитать количество разных букв, использованных в нем, а потом поделить эти количества на общее число букв. Получатся так называемые частоты букв. Так вот эти частоты практически всегда одинаковы для любых текстов, особенно больших.
2. Подбор и проверка сочетаний. Иногда можно успешно подобрать слова, если они заведомо используются в зашифрованном тексте. Например, если ты знаешь, что шпион передаёт в свой штаб информацию о новом виде вооружения, то наверняка в тексте найдётся название этого вооружения. «Внимание, штаб! Атакующая сторона намерена использовать рогатки». Если вы с друзьями и впрямь намерены использовать рогатки, то резонно предположить, что где-то в тексте есть это слово.
3. Наращивание объёма сообщений. Если шпион передаёт небольшие сообщения, то к ним сложно применить методы частотного анализа, а подбор сочетаний становится иногда делом бессмысленным. В этом случае надо набраться терпения и подождать новых сообщений, которые увеличат объём шифрованного текста. Тогда и можно будет применить оба предыдущих метода.
Эти три метода, используемые вместе или по отдельности, позволяют взломать практически любое сообщение, скрытое шифром простой подстановки (именно так называется этот способ шифрования). Но теперь ты можешь понять, как избежать быстрого взлома шифровки. Нужно сделать использование этих трёх методов невозможным. Во-первых, применять такие методы шифрования, которые изменяют частоту символов. Во-вторых, использовать так называемые коды – когда уязвимые для взлома понятия обозначаются специальными словами, кодами. В-третьих, настоящий шпион никогда не использует один и тот же шифр два раза. Никогда!
Об этих методах шифрования мы поговорим позднее. А теперь предлагаю заняться взломом.
Вот, например, тебе пришло письмо, в котором есть такой текст:

Первый взгляд на этот текст заставляет отбросить «это» и заявить, что разгадать его смысл невозможно. Но так ли это? Давай попробуем разобраться.
Выше я уже говорил, что замена символов, которыми обозначаются буквы, не влияет на частоты букв. Именно этим мы сейчас и воспользуемся. Для начала я приведу таблицу, про которую в первую очередь вспоминает всякий уважающий себя криптоаналитик. Вот она:

О чём эта таблица? В ней указаны частоты встречаемости букв в русском языке в обычных текстах. Как видишь, буква «О» встречается чаще всего. Можно сказать, что каждая десятая буква в тексте на русском языке, – это буква «О». Второе место занимает буква «Е» (вместе с «Ё»). Далее, соответственно, идут буквы «А», «И» и т. д. Самая редкая буква в русском языке – «Ъ».
Теперь я приведу примерный алгоритм, то есть последовательность шагов для расшифровки сообщения. Вот он:
1. Сначала надо точно подсчитать количество букв в сообщении. Для этого можно взять чистый лист бумаги в клетку и для каждого символа шифрограммы откладывать одну незаполненную клеточку. Клеточки, соответствующие пробелам, надо подчёркивать. После того как всё сообщение будет переведено в клеточки, надо просто посчитать пустые клетки без подчёркиваний.
2. Дальше следует построить таблицу. В ней должно быть два столбца и столько строк, сколько разных символов используется в шифрограмме. В первый столбец надо вписать все использованные символы.
3. Затем необходимо подсчитать количество каждого из отдельных символов и записать результаты во второй столбец. Это самая занудная часть алгоритма, но сделать это необходимо. Может быть, это займёт у тебя очень много времени, поэтому приступай к подсчетам, только когда у тебя есть возможность и желание заниматься. Как только ты устанешь, надо отложить это занятие и заняться чем-нибудь другим. Так за несколько подходов ты сможешь довести дело до конца.
4. После того как частоты всех символов посчитаны, надо нарисовать ещё одну такую же таблицу. Однако теперь записывай в нее символы по убыванию частоты. В первой строке должен находиться самый часто встречаемый символ и его количество в тексте. Во второй строке – следующий по частоте и т. д. Ты уже понимаешь, к чему мы ведём?
5. Теперь организуй рабочий цикл. В шифрограмме ты видишь символ, который встречается чаще всего. А в русском языке чаще всего встречается буква «О». Можно выдвинуть гипотезу, то есть сделать предположение, что этот символ и есть буква «О». После этого впиши букву «О» в тот самый размеченный лист, с помощью которого мы считали буквы в сообщении – в те клетки, которые соответствуют самому часто встречающемуся символу.
6. Теперь посмотри на частично разгаданный текст. В нём могут встретиться слова, о значении которых можно догадаться. Например, если есть слово из двух букв, стоящее после запятой, и вторая буква в этом слове – «О», то наверняка это слово «НО». А уж если оно встречается несколько раз, и всегда после запятой, то это точно слово «НО». Значит, теперь у нас есть вторая буква – «Н». Но если таких предположений сделать нельзя, то надо вернуться к шагу 5 и предположить значение следующего неразгаданного и наиболее часто встречающегося символа.
7. К таблице, которую мы заполняли на шаге 4, необходимо пририсовать ещё один столбец. В него мы будем записывать расшифровки символов.
Так, повторяя шаги 5 и 6, ты сможешь расшифровать весь текст. Однако иногда предположения относительно соответствия символов могут оказаться неверными. Это часто происходит, когда разгаданных символов ещё не так много, чтобы уже можно было видеть целые слова, а частоты разгадываемых символов примерно одинаковы. Тогда надо делать шаг назад в рассуждениях и выносить иное предположение. Также возможно, что в шифрограмме намеренно снижены или повышены частоты некоторых букв, и это может ввести в заблуждение. Но грамотный криптоаналитик в конце концов расшифрует и такой текст.
Давай попробуем разгадать по этому алгоритму ту шифрограмму, которая приведена несколькими страницами раньше. А после этого ты сможешь самостоятельно сделать то же самое с любой другой шифрограммой, текст в которой зашифрован этим способом, но, возможно, при помощи других значков.
Итак, в шифрограмме 419 букв (если твой результат отличается на пару букв, это не страшно, поскольку такая неточность не повлияет на результаты. А вот если ты ошибёшься на десяток букв, то тут уже придётся пересчитывать).
Теперь начнём считать частоты символов. В результате должна получиться примерно такая таблица:
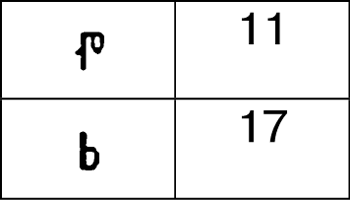

Надеюсь, что ты заполнишь все остальные строки самостоятельно.
После того как таблица будет построена, строчки необходимо отсортировать по убыванию количества символов. Если это сделать, то в результате получится что-то вроде этого:

Как видно, здесь частота первых двух символов отличается только на единицу. Это очень неприятная ситуация, поскольку придётся делать гипотезы и проверять их. Впрочем, криптоаналитик при дешифровке всегда строит гипотезы и пытается их проверить. Так что давай сейчас построим одну гипотезу. Поскольку самой частой буквой в русском языке является «О», то предположим, что значок из первой строки отсортированной таблицы – это и есть буква «О». Что получится, если в соответствии с догадкой подставить эту букву в наш текст? Вот:
−−−−−−. −−−−−−−, −−О − −−−− −−− −О−−−−−О−−, − −− −−−−−−− −−О− −−−−−. −−−− −−О −−−, −О − −О−− −О−−−−−−− −О−О−. −−− −− −−−−−− −О−−−−−−−, −−−− −−О−−О− −О−−−−−О−−− −О−−−−−−−О −− −О−−−−− −−− −−−−−−−−− −−−− − −−−−−−О−. −О−−О−− −−−О−−− −− −− −О−−−−−−−. − −−−−−−− −−−− − −−−−− −−−−−−− −− −−−−−−−, −−− −О−−О −−−−−−О−−−− −−О− −О−−−−−− −−−, −−О−− −−−−О −− −О− −− −−−−−−−− (−−О−− −−−, −О−− −− −О−−−−−− −−О− −−−−−−−). −−О −− −−− −−О−−О, −−− −−О −О−−−−−− − −−−−−−−− −−−−−−−−−, −−О−О −− −−− −−−−−− −−−−− − −−−−− −−−О−−О−−−−−−О.
Не очень-то понятно. Тем не менее это уже что-то.
Что делать дальше? Теперь попробуем подставить следующую по частоте букву. Для русского языка это буква «Е», так что подставим её вместо символа, занимающего вторую строчку в отсортированной таблице. Вот что получится после этого:
−−−−−Е. −−−−−−−, −ЕО − Е−−− −−− −О−−−−−О−−, − Е− −−Е−−−− −ЕОЕ Е−−−Е. −−−− −ЕО Е−−, ЕО − −О−− −О−−−Е−−− ЕО−О−. −−− Е− Е−−−−− −О−−−−−−−, −−−− −−О−ЕО− −О−−Е−−О−−− −О−−−−−−−О −− −О−−Е−− −−− −−−−−−−−− Е−−− − −−−−−ЕО−. −О−ЕО−− −−−О−−− −− −− −О−−−−−−−. − Е−−−−−− −−Е− − −−−−− −−−−Е−− Е− −−−−−−−, −−− −О−−О −−−−−−О−−Е− −−О− −О−−−−−− Е−−, −ЕО−− −−−ЕО −− −О− −− −−−−−−Е− (−−О−− Е−−, −О−− Е− −О−−−−−− −−О− −−−−−Е−). −ЕО −− Е−− −−О−−О, Е−− −ЕО −О−−−−−− − −−−−−−−− Е−−−−−−−−, −−О−О Е− −−− −−−−−− −−−Е− − −−−Е− −−−О−ЕО−Е−−−−О.
Сразу видно, что тут что-то не то. Во-первых, можно обратить внимание на слово «ЕО» в первой строке (шестнадцатое слово). Такого слова нет в русском языке. Во-вторых, в тексте неоднократно встречается не до конца разгаданное слово «−ЕО», причём на первом месте стоит один и тот же символ (это слово встречается четыре раза). Какие слова из трёх букв, подходящие под эту форму, есть в русском языке? Посмотрим: ГЕО (довольно редкое болгарское имя), ЛЕО (фамилия или имя из английского языка), НЕО (это из «Матрицы») и РЕО (город во Франции). Как видно, обычного русского слова нет ни одного, и можно предположить, что мы неверно расшифровали первые буквы. Впрочем, уже несуществующее слово «ЕО» позволяет отбросить гипотезу насчёт буквы «Е».
Теперь ты понимаешь, что «короткие» слова на первом этапе могут принести очень большую пользу. Именно на короткие слова надо обращать внимание, когда ты только приступаешь к расшифровке секретного сообщения. Давай пойдём дальше. Таким же образом можно отвергнуть гипотезы о том, что этот второй символ – буква «А» (третья по частоте) или буква «И» (четвёртая). Да, слова «АО» (сокращение от «автономный округ») и «ИО» (спутник Юпитера или имя нимфы из греческой мифологии) в русском языке есть, но они редкие и вряд ли окажутся в этом тексте.
Идём дальше. Следующая по частоте буква – это «Н». Тут, казалось бы, всё нормально, поскольку слово «НО» в русском языке есть, и оно как раз часто стоит после запятой. И буквосочетание «−НО» может означать часто встречающееся слово «ОНО» (но не в нашем случае, ты же понимаешь почему?). Попробуем сформулировать гипотезу и заменить символ буквой:
−−−−−Н. −−−−−−−, −НО − Н−−− −−− −О−−−−−О−−, − Н− −−Н−−−− −НОН Н−−−Н. −−−− −НО Н−−, НО − −О−− −О−−−Н−−− НО−О−. −−− Н− Н−−−−− −О−−−−−−−, −−−− −−О−НО− −О−−Н−−О−−− −О−−−−−−−О −− −О−−Н−− −−− −−−−−−−−− Н−−− − −−−−−НО−. −О−НО−− −−−О−−− −− −− −О−−−−−−−. − Н−−−−−− −−Н− − −−−−− −−−−Н−− Н− −−−−−−−, −−− −О−−О −−−−−−О−−Н− −−О− −О−−−−−− Н−−, −НО−− −−−НО −− −О− −− −−−−−−Н− (−−О−− Н−−, −О−− Н− −О−−−−−− −−О− −−−−−Н−). −НО −− Н−− −−О−−О, Н−− −НО −О−−−−−− − −−−−−−−− Н−−−−−−−−, −−О−О Н− −−− −−−−−− −−−Н− − −−−Н− −−−О−НО−Н−−−−О.
Час от часу не легче. Но тут легко можно заметить одиннадцатое слово «−НОН», причём первой буквой у него стоит та же, что и в слове «−НО». В русском языке есть слово «ОНОН» (река в Сибири), но оно не подходит, поскольку букву «О» мы уже отгадали. То есть гипотеза о букве «Н» – некорректная. Попробуем следующую букву, и если она не подойдёт, то придется поставить под сомнение самую первую гипотезу о букве «О». Следующая по частоте буква – это буква «Т». Подставим:
−−−−−Т. −−−−−−−, −ТО − Т−−− −−− −О−−−−−О−−, − Т− −−Т−−−− −ТОТ Т−−−Т. −−−− −ТО Т−−, ТО − −О−− −О−−−Т−−− ТО−О−. −−− Т− Т−−−−− −О−−−−−−−, −−−− −−О−ТО− −О−−Т−−О−−− −О−−−−−−−О −− −О−−Т−− −−− −−−−−−−−− Т−−− − −−−−−ТО−. −О−ТО−− −−−О−−− −− −− −О−−−−−−−. − Т−−−−−− −−Т− − −−−−− −−−−Т−− Т− −−−−−−−, −−− −О−−О −−−−−−О−−Т− −−О− −О−−−−−− Т−−, −ТО−− −−−ТО −− −О− −− −−−−−−Т− (−−О−− Т−−, −О−− Т− −О−−−−−− −−О− −−−−−Т−). −ТО −− Т−− −−О−−О, Т−− −ТО −О−−−−−− − −−−−−−−− Т−−−−−−−−, −−О−О Т− −−− −−−−−− −−−Т− − −−−Т− −−−О−ТО−Т−−−−О.
Вновь обратим внимание на слова «−ТО» и «−ТОТ», у которых первая буква одинаковая. Тут вариант один: первая буква – это «Э». Попробуем подставить:
−−−−−Т. −−−−−−−, −ТО − Т−−− −−− −О−−−−−О−−, − Т− −−Т−−−− ЭТОТ Т−−−Т. −−−− ЭТО Т−−, ТО − −О−− −О−−−Т−−− ТО−О−. −−− Т− Т−−−−− −О−−−−−−−, −−−− −−О−ТО− −О−−Т−−О−−− −О−−−−−−−О −− −О−−Т−− −−− −−−−−−−−− Т−−− − −−−−−ТО−. −ОЭТО−− −−−О−−− −− −− −О−−−−−−−. − Т−−−−−− −−Т− − −−−−− −−−−Т−− Т− −−−−−−−, −−− −О−−О −−−−−−О−−Т− −−О− −О−−−−−− Т−−, −ТО−− −−−ТО −− −О− −− −−−−−−Т− (−−О−− Т−−, −О−− Т− −О−−−−−− −−О− −−−−−Т−). ЭТО −− Т−− −−О−−О, Т−− −ТО −О−−−−−− − −−−−−−−− Т−−−−−−−−, −−О−О Т− −−− −−−−−− −−−Т− − −−−Т− −−−О−ТО−Т−−−−О.
Пока всё нормально. Никаких противоречий на первый взгляд нет. Более того: в тексте встречается последовательность «−ОЭТО−−». В этом слове из семи букв открыты четыре, так что можно попробовать догадаться, какое это слово. Поиск по словарю даёт только одно слово: «ПОЭТОМУ». Более того, перед «ПОЭТОМУ» часто пишется запятая, как и в этом случае. Получается, что мы сейчас смогли выдвинуть вполне правдоподобную гипотезу относительно ещё трёх скрытых символов. Пора составить новую таблицу и заполнить её:

Подставим-ка все известные на текущий момент символы в шифрограмму. Вот что получится:
П−−−−Т. −−−−−−−, −ТО У Т−−− −−− ПО−У−−−О−−, − Т− −−Т−−−− ЭТОТ Т−−−Т. −−−− ЭТО Т−−, ТО − МО−У −О−−−Т−−− ТО−О−. −−− Т− Т−П−−− ПО−−М−−−−, −−−− П−О−ТО− ПО−−Т−−О−−− −О−−−−−−−О −− −О−−Т−− −−− −−−−−−−−− Т−−− − −−−−−ТО−. ПОЭТОМУ −−−О−−− −М −− ПО−−−У−−−. − Т−−−−−− −−Т− − −−−−− −−−−Т−− Т− У−−−−−−, −−− МО−−О −−−−−−О−−Т− −−О− ПО−−−−−− Т−−, −ТО−− −−−ТО −− МО− −− −−−−−−Т− (−−ОМ− Т−−, −ОМУ Т− −О−−−−−− −−О− −−−−−Т−). ЭТО −− Т−− −−О−−О, Т−− −ТО −О−−−−−− − −−П−−−−− Т−−П−−−−М, −−О−О Т− −−− −У−−−− −−−Т− − УМ−Т− −−МО−ТО−Т−−−−О.
Сразу бросается в глаза первое слово. Ты ещё не догадываешься, что это за слово такое? Тогда подумай, какое слово из шести букв обычно ставят в начале письма, причём начинается оно на «П», а заканчивается на «Т»: «П−−−−Т». Ну, конечно же, это слово «ПРИВЕТ». Ура, у нас есть ещё четыре буквы. Давай внесём их в таблицу расшифровок: