Машинное обучение, глубокое обучение, нейронные сети
Прежде чем мы углубимся в то, как работает ИИ, и его различные варианты использования и приложения, давайте еще раз вернемся к терминам и концепциям ИИ, и разберем понятия искусственного интеллекта, машинного обучения, глубокого обучения и нейронных сетей.

Эти термины иногда используются взаимозаменяемо, но они не относятся к одному и тому же.
Искусственный интеллект – это область информатики, занимающаяся симуляцией интеллектуального поведения.
Системы ИИ, как правило, демонстрируют поведение, связанное с человеческим интеллектом, такое как планирование, обучение, рассуждение, решение задач, представление знаний, восприятие, движение и манипуляция, и в меньшей степени социальный интеллект и креативность.
Машинное обучение – это подмножество ИИ, которое использует компьютерные алгоритмы для анализа данных и принятия разумных решений на основе того, что они узнали, без явного программирования.
Алгоритмы машинного обучения обучаются на больших наборах данных и учатся на примерах.
Они не следуют алгоритмам, основанным на правилах.
Машинное обучение – это то, что позволяет машинам самостоятельно решать задачи и делать точные прогнозы, используя предоставленные данные.
Глубокое обучение – это специализированный раздел машинного обучения, который использует многоуровневые нейронные сети для имитации принятия человеческих решений.
Алгоритмы глубокого обучения могут маркировать и классифицировать информацию и идентифицировать шаблоны – закономерности.
Это то, что позволяет системам искусственного интеллекта постоянно учиться в процессе работы и повышать качество и точность результатов, определяя правильность принятых решений.
Идея искусственных нейронных сетей основывается на биологических нейронных сетях, хотя они работают совсем по-другому.

Нейронная сеть в ИИ представляет собой набор небольших вычислительных блоков, называемых нейронами, которые принимают входящие данные и учатся принимать решения с течением времени.
Нейронные сети часто являются многоуровневыми и становятся более эффективными по мере увеличения объема наборов данных, в отличие от других алгоритмов машинного обучения.
Теперь, давайте разберем еще одно важное различие, которое важно понять, – это различие между искусственным интеллектом и наукой о данных.
Наука о данных – это процесс и метод извлечения знаний и идей из больших объемов разнородных данных.
Это междисциплинарная область, включающая математику, статистический анализ, визуализацию данных, машинное обучение и многое другое.
Это то, что позволяет нам обрабатывать информацию, видеть закономерности, находить смысл в больших объемах данных и использовать информацию для принятия решений.
И наука о данных, Data Science может использовать многие методы искусственного интеллекта, чтобы получить представление о данных.
Например, наука о данных может использовать алгоритмы машинного обучения и даже модели глубокого обучения, чтобы извлечь смысл и сделать выводы из данных.
Существует некоторое пересечение между ИИ и наукой о данных, но одно не является подмножеством другого.
Наоборот, наука о данных – это более широкий термин, охватывающий всю методологию обработки данных.
А ИИ включает в себя все, что позволяет компьютерам учиться решать задачи и принимать разумные решения.
И ИИ, и Data Science могут использовать большие данные.
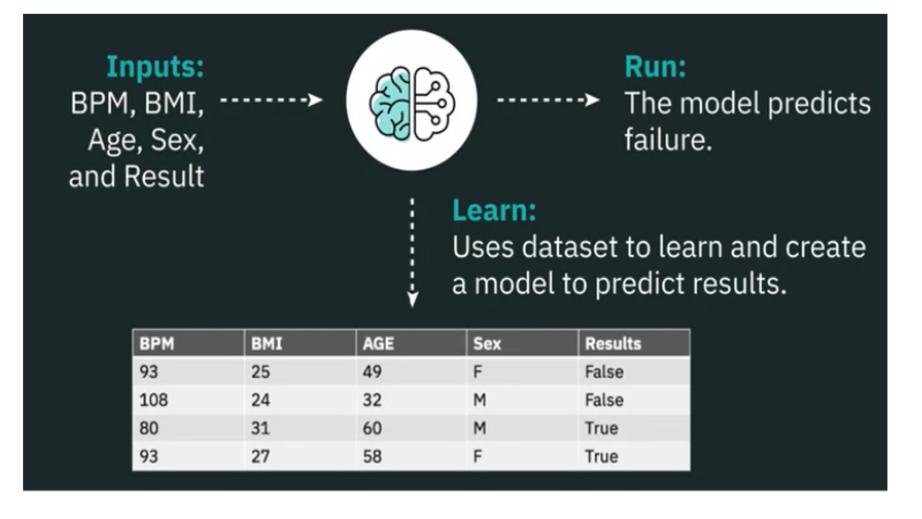
Машинное обучение, подмножество искусственного интеллекта, использует компьютерные алгоритмы для анализа данных и принятия разумных решений на основе того, что алгоритмы изучили.
Вместо того, чтобы следовать алгоритмам, основанным на правилах, машинное обучение само строит модели для классификации и прогнозирования на основе данных.
Например, что, если мы хотим определить, может ли возникнуть проблема с нашим сердцем, с помощью машинного обучения?
Можем ли мы это сделать.
И ответ – да.
Допустим, нам даны такие данные, как количество ударов в минуту, вес тела, возраст и пол.
С машинным обучением и этим набором данных, мы можем изучить и создать модель, которая с учетом входных данных будет предсказывать результаты.
Так в чем же разница между этим подходом и просто использования статистического анализа для создания алгоритма?
Алгоритм – это математическая техника.
В традиционном программировании мы берем данные и правила и используем их для разработки алгоритма, который даст нам ответ.
В этом примере, если бы мы использовали традиционный алгоритм, мы бы взяли данные, такие как сердечный ритм, возраст, вес тела и пол и использовали эти данные для создания алгоритма, который определит, будет ли сердце работать нормально или нет.
По сути, это было бы выражение if – else.
Когда мы отправляем входные данные, мы получаем ответы, основанные на том, какой алгоритм мы определили, и этот алгоритм не изменится от данных.
Машинное обучение, с другой стороны, берет данные и ответы и уже потом само создает алгоритм.
Вместо того, чтобы получить ответы в конце, у нас уже есть ответы.
А то, что мы получаем здесь, – это набор правил, определяющих модель машинного обучения.
И эта модель определяет правила и оператор if – else при получении входных данных.
И эта модель, в отличие от традиционного алгоритма, может постоянно обучаться и использоваться в будущем для прогнозирования значений.
Машинное обучение опирается на определение правил путем изучения и сравнения больших наборов данных, чтобы найти общие закономерности.
Например, мы можем создать программу машинного обучения с большим объемом изображений птиц, и обучить модель возвращать название птицы всякий раз, когда мы даем изображение птицы.
Когда для модели отображается изображение птицы, она маркирует изображение с некоторой степенью достоверности.
Этот тип машинного обучения называется контролируемым обучением, где алгоритм обучается на данных, размеченных человеком.

Чем больше примеров мы предоставляем контролируемому алгоритму обучения, тем точнее он производит классификацию новых данных.
Неуправляемое обучение, это еще один тип машинного обучения, которое основывается на предоставлении алгоритму неразмеченных данных и позволяет ему самостоятельно находить шаблоны.
Вы предоставляете просто входные данные, и позволяете машине делать выводы и находить шаблоны.
Этот тип обучения может быть полезен для кластеризации данных, когда данные группируются в соответствии с тем, насколько они похожи на своих соседей и отличаются от всего остального.
Как только данные кластеризованы, можно использовать различные методы для изучения этих данных и поиска шаблонов.
Например, можно создать алгоритм машинного обучения с постоянным потоком сетевого трафика и позволить ему независимо изучать активность в сети – базовый уровень, нормальную сетевую активность, а также выбросы и, возможно, злонамеренное поведение, происходящее в сети.

Третий тип алгоритма машинного обучения, обучение с подкреплением, это алгоритм машинного обучения с набором правил и ограничений и позволяет ему учиться достигать целей.
Вы определяете состояние, желаемую цель, разрешенные действия и ограничения.
И алгоритм выясняет, как достичь цели, пробуя различные комбинации разрешенных действий, и его награждают или наказывают в зависимости от того, было ли решение правильным.
Алгоритм изо всех сил старается максимизировать свои вознаграждения в рамках предусмотренных ограничений.
И вы можете использовать обучение с подкреплением, чтобы научить машину играть в шахматы или преодолеть какие-либо препятствия.
Таким образом, машинное обучение – это широкая область, и мы можем разделить его на три разные категории: контролируемое обучение, неконтролируемое обучение и обучение с подкреплением.
И есть много разных задач, которые мы можем решить с помощью них.
В контролируемом обучении, в наборе данных есть метки, и мы используем их для построения модели классификации данных.
Это означает, что, когда мы получаем данные, у них есть метки, которые говорят о том, что представляют эти данные.
В примере с сердцем, у нас была таблица с метками, это сердечный ритм, возраст, пол и вес.
И каждой такой метке соответствовали значения.
При неконтролируемом обучении у нас нет меток, и мы должны обнаружить эти метки в неструктурированных данных.
И такие вещи обычно делаются с помощью кластеризации.
Обучение с подкреплением – это другое подмножество машинного обучения, и оно использует вознаграждение для наказания за плохие действия или вознаграждение за хорошие действия.

И мы можем разделить контролируемое обучение на три категории: регрессия, классификация и нейронные сети.
Модели регрессии строятся с учетом взаимосвязей между признаками x и результатом y, где y – непрерывная переменная.
По сути, регрессия оценивает непрерывные значения.
Нейронные сети относятся к структурам, которые имитируют структуру человеческого мозга.
Классификация, с другой стороны, фокусируется на дискретных значениях, которые она идентифицирует.
Мы можем назначить дискретные результаты y на основе многих входных признаков x.
В примере с сердцем, учитывая набор признаков x, таких как удары в минуту, вес тела, возраст и пол, алгоритм классифицирует выходные данные y как две категории: истина или ложь, предсказывая, будет ли сердце работать нормально или нет.
В других классификационных моделях мы можем классифицировать результаты по более чем двум категориям.
Например, прогнозирование, является ли данный рецепт рецептом индийского, китайского, японского или тайского блюда.
И с помощью классификации мы можем извлечь особенности из данных.
Особенности в этом примере сердцем, это сердечный ритм или возраст.
Особенности – это отличительные свойства шаблонов ввода, которые помогают определить категории вывода.

Здесь каждый столбец является особенностью, а каждая строка – точкой ввода данных.
Классификация – это процесс прогнозирования категории заданных точек данных.
И наш классификатор использует обучающие данные, чтобы понять, как входные переменные относятся к этой категории.
Что именно мы подразумеваем под обучением?
Обучение подразумевает использование определенного алгоритма обучения для определения и разработки параметров модели.
Хотя для этого есть много разных алгоритмов, с точки зрения непрофессионала, если вы тренируете модель, чтобы предсказать, будет ли сердце работать нормально или нет, есть истинные или ложные значения, и вы будете показывать алгоритму некоторые реальные данные, помеченные как истинные, затем снова показывая данные, помеченные как ложные, и вы будете повторять этот процесс с данными, имеющими истинные или ложные значения.
И алгоритм будет изменять свои внутренние параметры до тех пор, пока он не научится распознавать данные, которые указывают на то, что есть сердечная недостаточность или ее нет.
При машинном обучении мы обычно берем набор данных и делим его на три набора: наборы обучения, проверки и тестирования.
Набор обучения – это данные, используемые для обучения алгоритма.
Набор проверки используется для проверки наших результатов и тонкой настройки параметров алгоритмов.
Данные тестирования – это данные, которые модель никогда не видела прежде и которые используются для оценки того, насколько хороша наша модель.
Опять же, чтобы повторить, модель машинного обучения – это алгоритм, используемый для поиска закономерностей в данных без программирования в явном виде.

В то время как машинное обучение является подмножеством искусственного интеллекта, глубокое обучение является специализированным подмножеством машинного обучения.
Глубокое обучение основывается на алгоритмах машинного обучения, которые основываются на структуре и функциях мозга, и эти алгоритмы называются искусственными нейронными сетями.
Эти сети предназначены для непрерывного обучения в процессе работы для повышения качества и точности результатов.
Эти системы могут обучаться на неструктурированных данных, таких как фотографии, видео и аудиофайлы.
Алгоритмы глубокого обучения напрямую не отображают входные данные в выходные.
Вместо этого они полагаются на несколько слоев обработки.
Каждый такой слой передает свой вывод следующему слою, который обрабатывает его и передает его следующему.
Именно поэтому такая система из многочисленных слоев называется глубоким обучением.
При создании алгоритмов глубокого обучения разработчики и инженеры настраивают количество слоев и тип функций, которые соединяют выходы каждого слоя со входами следующего.
Затем они обучают модель, предоставляя множество размеченных примеров.
Например, вы даете алгоритму глубокого изучения тысячи изображений и метки, которые соответствуют содержанию каждого изображения.
Алгоритм будет запускать эти примеры через свою многоуровневую нейронную сеть и будет подгонять веса переменных в каждом слое нейронной сети, чтобы иметь возможность обнаруживать общие шаблоны, которые определяют изображения с похожими метками.
Глубокое обучение устраняет одну из основных проблем, с которой сталкивались алгоритмы обучения предыдущего поколения.
В то время как эффективность и производительность алгоритмов машинного обучения предыдущего поколения не улучшалась по мере роста наборов данных, алгоритмы глубокого обучения продолжают улучшаться по мере поступления большего количества данных.
Глубокое обучение оказалось очень эффективным при выполнении различных задач, включая распознавание и транскрипцию голоса, распознавание лиц, медицинскую визуализацию и языковой перевод.
Глубокое обучение также является одним из основных компонентов беспилотных автомобилей.

Искусственная нейронная сеть представляет собой совокупность мелких единиц, называемых нейронами, которые представляют собой вычислительные единицы, смоделированные по способу обработки информации человеческим мозгом.
Искусственные нейронные сети заимствуют некоторые идеи из биологической нейронной сети мозга, чтобы приблизить некоторые результаты его обработки.
Эти единицы или нейроны принимают поступающие данные, также как и биологические нейронные сети, и со временем учатся принимать решения.
Нейронные сети учатся через процесс, называемый обратным распространением.
Например, при преобразовании речи в текст, в нейронных сетях вместо кодирования правил вы предоставляете образцы голоса и соответствующий им текст.
И нейронная сеть находит общие шаблоны произношения слов, а затем учится сопоставлять новые голосовые записи с соответствующими им текстами.
YouTube использует это для автоматического создания субтитров.
Обратное распространение использует набор обучающих данных, которые сопоставляют известные входы с желаемыми выходами.
Сначала входы подключаются к сети и определяются выходы.
Затем функция ошибки определяет, насколько далеко данный выход находится от желаемого выхода.
И наконец, делаются изменения, чтобы уменьшить ошибки.

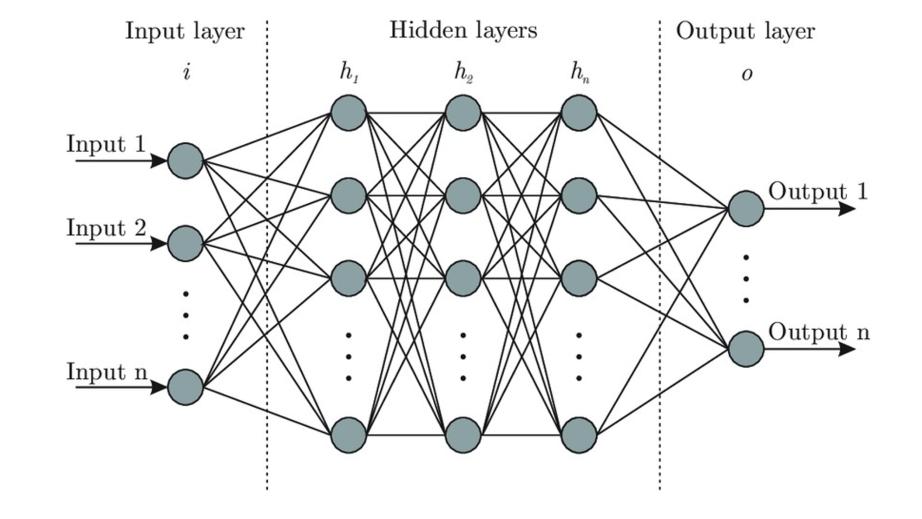
Набор нейронов называется слоем, и слой принимает входные данные и обеспечивает выходные данные.
Любая нейронная сеть будет иметь один входной слой и один выходной слой.
И нейронная сеть также будет иметь один или несколько скрытых слоев, которые имитируют типы деятельности, происходящих в человеческом мозге.
Скрытые слои принимают набор взвешенных входных данных и выдают результат с помощью функции активации.
Нейронная сеть, имеющая более одного скрытого слоя, называется глубокой нейронной сетью.
Перцептроны – это самые простые и старые типы нейронных сетей.
Это однослойные нейронные сети, состоящие из входных узлов, подключенных непосредственно к выходному узлу.

Входные слои передают входные значения следующему слою путем умножения на вес и суммирования результатов.
Скрытые слои получают входные данные от других узлов и направляют свои выходные данные на другие узлы.

Скрытые и выходные узлы имеют свойство, называемое смещением bias, которое представляет собой особый тип веса, который применяется к узлу после рассмотрения других входных данных.

И наконец, функция активации определяет, как узел реагирует на свои входные данные.
Функция запускается на сумме входов и смещения, а затем результат передается как выходной.
Функции активации могут принимать различные формы, и их выбор является критическим компонентом успеха нейронной сети.

Сверточные нейронные сети или CNN представляют собой многослойные нейронные сети, которые основываются на работе зрительной коры животных.
CNN полезны в таких приложениях, как обработка изображений, распознавание видео и обработка языка.
Свертка – это математическая операция, в которой функция применяется к другой функции, а результат представляет собой смесь двух функций.
Свертки хороши при обнаружении простых структур на изображении и объединении этих простых функций для создания более сложных функций.
В сверточной сети этот процесс происходит в последовательности слоев, каждый из которых проводит свертку на выходе предыдущего слоя.
CNN являются экспертами в построении сложных функций из менее сложных.
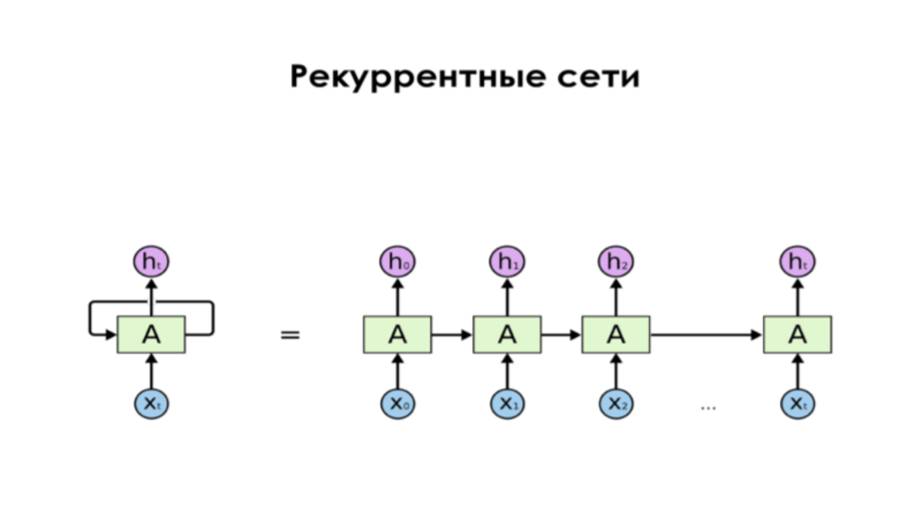
Рекуррентные нейронные сети или RNN являются рекуррентными, потому что они выполняют одну и ту же задачу для каждого элемента последовательности, причем предыдущие выходы питают входы последующих этапов.
В обычной нейронной сети вход обрабатывается через несколько слоев, а выход создается с допущением, что два последовательных входа независимы друг от друга, но это может не выполняться в определенных сценариях.
Например, когда нам нужно учитывать контекст, в котором было произнесено слово, в таких сценариях необходимо учитывать зависимость от предыдущих наблюдений, чтобы получить результат.
И RNN могут использовать информацию в длинных последовательностях, причем каждый уровень сети представляет наблюдение в определенное время.

Новый тип нейронной сети, называемый порождающей состязательной сетью (GAN), может использоваться для создания сложных выходных данных, таких как фотореалистичные изображения.
На странице сайта IBM вы можете попробовать создать изображение с помощью GAN.
В разделе «Совместное создание с нейронной сетью» в разделе «Выберите сгенерированное изображение» выберите одно из существующих изображений.
И в списке Pick object type выберите тип объекта, который вы хотите добавить.
Например, нажмите на дерево.

Переместите курсор на изображение.
Нажмите и удерживая кнопку мыши нажатой, наведите курсор на область существующего изображения, в которую вы хотите добавить объект, в данном случае дерево.
Выберите другой тип объекта и добавьте его к изображению.
Поэкспериментируйте: можете ли вы поместить дверь в небо?
И используйте функции отмены и удаления, чтобы удалить объекты.
И нажмите «Загрузить», чтобы сохранить свою работу.