Глава 2. Числовые характеристики выборки и представление данных
Можно ли доверять мудрости толпы?
В 1907 году Фрэнсис Гальтон (двоюродный брат Чарльза Дарвина, эрудит, создатель метода идентификации отпечатков пальцев, метеоролог и автор термина «евгеника»[37]) написал письмо в престижный научный журнал Nature о своем посещении выставки животноводства и птицеводства в Плимуте. Там он увидел необычный конкурс: участникам, заплатившим по 6 пенсов, предлагалось угадать вес выставленного напоказ большого откормленного быка, после того как его забьют и освежуют. По окончании конкурса ученый взял 787 заполненных билетов и выбрал из них в качестве среднего значения 1207 фунтов (547 килограммов). «Любая иная оценка рассматривалась большинством голосовавших как слишком высокая или слишком низкая», – пояснил он. Реальный вес животного составил 1198 фунтов (543 килограмма), что оказалось на удивление близко к выбранному числу[38]. Гальтон назвал свое письмо Vox Populi («Глас народа»), хотя сегодня такой процесс принятия решений более известен как мудрость толпы.
Гальтон выполнил то, что сегодня мы назвали бы сводкой данных: он взял множество чисел на билетах и свел их к одному весу в 1207 фунтов. В этой главе мы рассмотрим методы, разработанные в последующем столетии для получения сводной информации из имеющейся массы данных. Мы увидим, что числовые характеристики выборки (показатели положения, распространения, разброса, тренды и корреляция) тесно связаны со способом их представления на бумаге или экране. Мы также поговорим о переходе от простого описания данных к сторителлингу с помощью инфографики.
Начнем с моей собственной попытки экспериментировать с мудростью толпы, которая выявляет многие из проблем, возникающих, когда в качестве источника данных используется реальный мир, со всей его склонностью к странностям и ошибкам.
Статистика касается не только таких серьезных вещей, как рак и хирургия. В рамках нашего с популяризатором математики Джеймсом Граймом довольно простого эксперимента мы выложили на YouTube видео и попросили угадать число драже в банке. Вы тоже можете попробовать это сделать, посмотрев на фотографию на рис. 2.1 (истинное число станет известно позже). Свои предположения высказали 915 человек, их ответы варьировались от 219 до 31 337. В этой главе мы увидим, как такие переменные можно изображать графически и обрабатывать численно.

Рис. 2.1
Сколько драже в банке? Мы спросили об этом в ролике на YouTube и получили 915 ответов. Ответ будет дан позже
Начнем с того, что на рис. 2.2 отображены три способа представления чисел, указанных 915 участниками. Их можно назвать по-разному: распределение данных, выборочное распределение или эмпирическое распределение[39].

Рис. 2.2
Различные способы отображения 915 предположений о количестве драже в банке: (a) точечная диаграмма с разбросом, чтобы точки не перекрывали друг друга; (b) диаграмма размаха, или «ящик с усами»; (c) гистограмма
(a) Точечная диаграмма просто показывает все значения в виде отдельных точек, но для каждой добавлено случайное отклонение по вертикали, чтобы точки не перекрывали друг друга, поскольку некоторые догадки были высказаны по несколько раз. Четко видна концентрация большого количества значений в диапазоне примерно до 3000, а затем длинный «хвост» тянется более чем за 30 000, причем в точке 10 000 наблюдается всплеск.
(b) Диаграмма размаха («ящик с усами») показывает некоторые базовые характеристики распределения[40].
(c) На гистограмме просто учитывается, сколько точек данных попало в тот или иной интервал. Она дает очень приблизительное представление о форме распределения.
Эти способы отображения сразу же позволяют выделить некоторые особенности распределения. Видно, что оно сильно скошено, то есть асимметрично (отсутствует даже приблизительная симметрия относительно какой-нибудь центральной точки) и из-за наличия нескольких очень больших чисел имеет длинный «правый хвост». Вертикальные ряды точек на точечной диаграмме (изображающие повторяющиеся числа) также указывают на некоторое предпочтение круглых чисел.
Однако у всех диаграмм есть общая проблема. Внимание сосредоточено на самых больших значениях, причем основная часть чисел сконцентрирована в левой части. Можно ли представить эти данные более информативно? Мы могли бы отбросить самые большие числа как нелепые (когда я первоначально анализировал полученные величины, я сознательно исключил все, превышающие 9000). Кроме того, мы можем уменьшить влияние экстремальных наблюдений, скажем, отобразив данные в логарифмическом масштабе, когда интервал от 100 до 1000 имеет такую же длину, что и интервал от 1000 до 10 000[41].
На рис. 2.3 представлена более понятная структура с вполне симметричным распределением и отсутствием значительных выбросов. Это избавляет нас от исключения каких-либо значений наблюдений, что обычно не считается хорошей идеей (если, конечно, речь не идет о явных ошибках).

Рис. 2.3
Графическое отображение догадок о числе драже в банке в логарифмическом масштабе: (a) точечная диаграмма; (b) «ящик с усами»; (c) гистограмма – на всех заметна достаточная степень симметрии
Единственно правильного способа отображения чисел нет, у каждого из способов свои преимущества: на точечной диаграмме показаны все отдельные точки, «ящик с усами» дает визуальное представление, а гистограмма помогает полнее понять вид исходного распределения.
Переменные, которые записываются в виде чисел, могут быть разного типа:
• Счетные переменные: могут принимать целочисленные значения 0, 1, 2, 3… Например, ежегодное число самоубийств или предположения о количестве драже в банке.
• Непрерывные переменные: могут принимать любые значения. Например, некоторые вещи теоретически можно измерять с любой точностью и получать любые числа. Скажем, вес и рост, которые отличаются как у разных людей, так и у одного человека в зависимости от времени. Разумеется, эти значения можно округлить до целого числа сантиметров или килограммов[42].
Когда набор наблюдений (выборка) сводится к одному числу, мы, как правило, называем его средним значением. Все знакомы с понятием средней зарплаты, средней оценки на экзамене или средней температуры, но часто не знают, как интерпретировать эти величины (особенно если человек, который о них говорит, сам не понимает, о чем речь).
Чаще всего встречаются три толкования термина «среднее значение»:
1. Среднее арифметическое (или выборочное среднее): сумма всех величин, деленная на их количество.
2. Медиана: среднее по величине число ранжированного ряда (то есть слева и справа от него будет поровну чисел)[43]. Именно так Гальтон считал голоса толпы[44].
3. Мода: чаще всего встречающееся значение в выборке.
Эти параметры также называются показателями положения центра распределения.
Интерпретация термина «среднее» как «среднее арифметическое» дает повод для старых шуток о том, что почти у всех людей число ног превышает среднее (которое, по оценкам, примерно равно 1,99999) и что у человека в среднем одно яичко. Однако среднее арифметическое может не подходить не только при измерении ног и яичек. Вычисленное таким образом среднее число сексуальных партнеров или средний доход по стране может иметь крайне мало общего с представлением большинства людей из-за сильного влияния больших значений в выборке, которые тянут среднее арифметическое вверх[45]: подумайте об Уоррене Битти или Билле Гейтсе (в отношении числа сексуальных партнеров и дохода соответственно).
Средние значения способны сильно вводить в заблуждение, когда исходные данные имеют не симметричное распределение, а сильно перекошенное в какую-либо сторону (как при догадках о количестве драже). Как правило, так происходит при наличии большой группы стандартных случаев и хвоста из нескольких высоких (скажем, величина дохода) или низких (число ног) значений. Я могу практически гарантированно утверждать, что вы гораздо меньше рискуете умереть в следующем году по сравнению с людьми вашего возраста и пола (если средний риск вычислять как среднее арифметическое). Например, согласно таблицам смертности для Соединенного Королевства, 1 % 63-летних мужчин не доживают до 64-летия. Однако многие из тех, кто умрет, уже серьезно больны, а потому риск для подавляющего большинства (тех, кто относительно здоров) меньше, чем средний.
К сожалению, когда в СМИ пишут о среднем, часто непонятно, следует это толковать как среднее арифметическое или как медиану. Например, Национальная статистическая служба Великобритании вычисляет средний недельный заработок (который рассчитывается как среднее арифметическое), а также публикует медианные заработки, предоставляемые местными органами. Это позволяет отличить «средний доход» (среднее арифметическое) от «дохода среднего человека» (медиана). Цены на дома имеют крайне асимметричное распределение с длинным правым хвостом элитной недвижимости, поэтому официальные индексы для цен на жилье указываются в виде медианных значений. Однако обычно пишут о «цене в среднем», что является весьма неоднозначным термином. Это «цена среднего дома» (то есть медиана)? Или «средняя цена дома» (то есть среднее арифметическое)? Как видите, перестановка слов имеет большое значение.
А теперь пришло время обнародовать результаты нашего эксперимента с мудростью толпы; может, он не такой захватывающий, как определение веса быка, зато с чуть большим количеством голосов, чем у Гальтона.
Из-за наличия длинного правого хвоста среднее арифметическое 2408 было бы плохой оценкой, а мода (чаще других названное значение) 10 000, похоже, отражает склонность людей выбирать круглые числа. Поэтому предпочтительнее последовать примеру Гальтона и использовать в качестве общей оценки медиану. Она равна 1775, хотя на самом деле в банке находилось 1616 драже[46]. Правильно это число угадал только один человек, 45 % дали оценки ниже этого значения, а 55 % – выше. Поэтому наблюдается небольшая асимметрия, и мы говорим, что истинное значение находится на 45-м процентиле[47]. Медиана, которая является 50-м процентилем, дала избыточную оценку: 1775–1616 = 159 и оказалась примерно на 10 % больше правильного ответа. Только каждый десятый человек указывал оценку лучше, чем полученное медианное значение. Таким образом, мудрость толпы оказалась вполне на уровне, а именно гораздо ближе к истине, чем 90 % отдельных людей.
Разброс распределения данных
Свести распределение к единственному числу недостаточно – нужно иметь представление о разбросе данных (рассеивании, отклонении от среднего). Например, знание среднего размера обуви взрослого мужчины никак не поможет обувной фабрике определить, сколько пар обуви каждого размера производить. Один размер не годится для всех, что прекрасно иллюстрируют пассажирские кресла в самолетах.
В табл. 2.1 приведены статистические данные для выборки по драже. Она предлагает три способа демонстрации разброса. Естественный вариант – размах[48], однако он крайне чувствителен к экстремальным значениям, таким как весьма странное предположение о наличии в банке 31 337 драже[49]. Напротив, на интерквартильный размах такие выбросы не очень влияют. Интерквартильный размах – это разность между третьим и первым квартилем (то есть 75-м и 25-м процентилем); иными словами, сюда входит «центральная половина» всех чисел, в нашем случае – от 1109 до 2599 драже. Ящик на диаграмме типа «ящик с усами» как раз и включает интерквартильный размах. Наконец, в качестве меры разброса широко используется стандартное (среднеквадратичное) отклонение. Но поскольку его сложнее вычислять и оно сильно подвержено влиянию выбросов, оно лучше всего подходит для симметричных и хорошо себя ведущих данных[50]. Например, удаление из выборки одного (почти гарантированно ошибочного) числа 31 337 приводит к уменьшению среднеквадратичного отклонения с 2422 до 1398[51].
Таблица 2.1
Характеристики выборки для 915 предположений о количестве драже в банке. Истинное число равно 1616
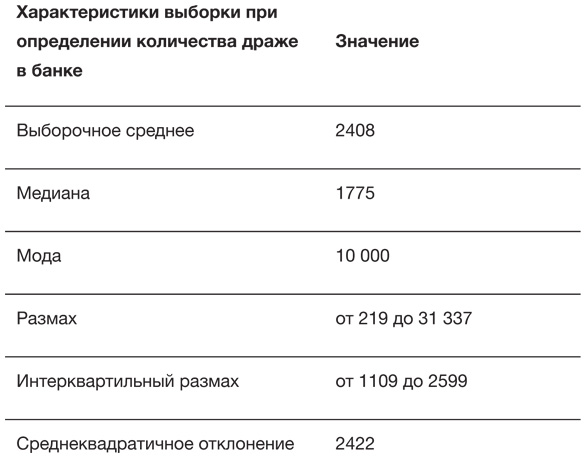
Толпа в нашем маленьком эксперименте продемонстрировала значительную мудрость, даже несмотря на несколько странных ответов. Это показывает, что, хотя данные часто включают ошибки, выбросы и другие странные величины, их вовсе не обязательно выискивать и исключать. Кроме того, это указывает на полезность использования характеристик выборки, на которые не влияют даже столь эксцентричные наблюдения, как 31 337. Такие характеристики называются робастными (то есть устойчивыми) и включают медиану и интерквартильный размах. Наконец, эксперимент подчеркивает ценность обычного просмотра данных – урок, который будет подкреплен следующим примером.
Разница между группами чисел