Глава 1. Базовые принципы маркетинговых исследований
Базовые принципы важно соблюдать всегда: при разработке инструментария, выделении сегментов, в аналитике, на каждом этапе маркетингового исследования. Нужно регулярно проверять все свои действия – соблюдается ли тот или иной базовый принцип. Как дом стоит на фундаменте, так и любое маркетинговое исследование строится с учетом базовых принципов. И если эти принципы не соблюдаются, то и результаты будут похожи на карточный домик, который в любую секунду может обрушиться, похоронив под собой бизнес.
Принцип однородности исследования
Однородность – равномерность, единообразие, близость, одинаковость, однотипность. Это значит, что собирать данные нужно, используя одну и только одну методику. А проводить анализ – отдельно по выделенным сегментам, которые отвечают конкретным характеристикам. И все полученные по разным сегментам или по разным методикам результаты можно сравнивать, но нельзя смешивать в один анализ.
Рассмотрим пример. Данные по одной задаче можно получить с помощью разных методов. Например, у нас стоит задача оценить стандарты обслуживания клиентов компании Z. Сбор данных проводится при помощи методов «Тайный покупатель» и опроса клиентов. В результате двух исследований мы получаем одни и те же данные – уровень выполнения стандартов обслуживания. Казалось бы, полученные данные можно собрать в одну кучу и проанализировать. Но на самом деле, это не так. Это изначальная ошибка, которая потом приведет к проблемам в бизнесе.
А теперь давайте разберемся, как мы получаем этот результат. Когда мы замеряем уровень стандартов обслуживания с помощью «тайных покупателей», мы получаем оценку, которую «тайный покупатель» сравнивает с известным ему единым стандартом. В случае с опросом, клиенту не известны стандарты обслуживания, принятые в компании Z. Клиент сам для себя определяет некие стандарты, которые – как ему кажется, – должны быть в компании, и сравнивает результат с ними.
То есть в случае с «тайным покупателем» происходит сравнение с реальными, принятыми в компании стандартами. А в случае опроса клиентов происходит сравнение со стандартами, известными только клиенту.
Как показано на рис. 1, данные, полученные с использованием разных методов, пересекаются, но мы не знаем, в какой плоскости, под каким углом, и в каком объеме. Таким образом, при смешивании в один анализ данных из разных методик или методов, мы из плоскости математики и статистики уходим в плоскость интуитивных гаданий.

В компании Z провели замеры стандартов обслуживания клиентов и получили следующие интересные данные. Консультантам компании был вменен стандарт «Выявление потребности клиентов». Но клиенты в эту компанию приходят с конкретным запросом и не знают о том, что консультант должен провести с ними определенную работу.
И что мы получаем в результате по данному стандарту обслуживания? «Тайные покупатели» поставили по нему очень низкие оценки, так как им были известны стандарты, принятые в компании. А клиенты компании Z во время опроса поставили высокие оценки, думая, что речь идет об уровне ответа консультанта на заданный ими вопрос.
Если мы эти данные, полученные с помощью разных методик, смешаем в одну кучу, то получим некую непонятную величину, никак не отражающую разницу между восприятием стандартов обслуживания клиентом, и самими стандартами, принятыми в компании. Ведь вполне возможно, что, например, стандарт «Инициативность консультанта» не предусматривает выявления потребностей клиентов, так как клиент приходит с конкретной задачей, и лучше сразу направить силы и время консультантов на процессы, более важные для клиента.
Порой руководство компаний перегружает сотрудников процессами, которые не важны для клиентов, а на значимые процессы у консультантов не остается времени и сил.
Принцип однородности должен соблюдаться, в том числе, и когда вы проводите кабинетные исследования. Когда вы планируете «пройтись» по конкурентам, изучая их работу. В книге принцип однородности исследования будет встречаться часто, и вы увидите примеры, где мы подробно разберем важность соблюдения этого принципа.
Выборка при опросах. «Истина где-то рядом»
Понятие репрезентативности известно уже давно. А калькулятор расчета ошибки выборки доступен любому пользователю Интернета. Тем не менее, часто маркетологи очень вольно обращаются с понятием репрезентативности. Выборку порой назначают (не рассчитывают, а именно назначают) из собственного внутреннего ощущения. Понятие внутренних ощущений в научном труде, (а исследование – это научный труд), сродни вождению автомобиля в нетрезвом виде. Исследователь, который вольно обращается с базовыми принципами, – потенциальный убийца бизнеса. Ведь на основе полученных данных будут построены стратегия и дальнейшие шаги развития компании. И вольное обращение с базовыми принципами построения исследования ведет к весьма вредным для бизнеса последствиям, так как исследование основано на субъективных данных, полученных на основе ощущений одного человека.
Рассуждения о том, стоит ли правильно считать выборку, – то же самое, что обсуждать правила математических вычислений на уровне «нравится – не нравится».
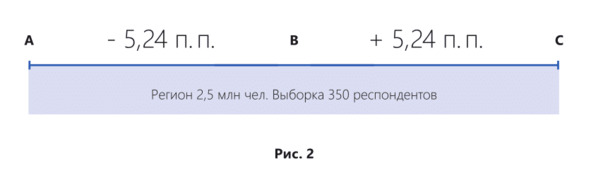
Рассмотрим пример из практики. Специалисты отдела маркетинга компании Z (компания работает в массовом сегменте) решили провести исследование в регионе с населением 2,5 млн человек и посчитали, что 350 респондентов достаточно для получения результатов.
Ошибка выборки в данном случае составит ± 5,24% при расчетах в натуральном выражении. В случае расчета в долях, процентах, ошибка выборки рассчитывается в процентных пунктах (п. п.)
Максимальное отклонение от истины в размере 5,24% возможно только в том случае, если результат исследований находится в точке «В», а истина находится в точке «А» или «С» (рис. 2).
Например, мы вычислили, что доля использования антифриза владельцами автомобилей старше 1997 г. в. составляет 10,6% – это результат. Значит истина находится в диапазоне от 5,36% до 15,84%. Вычисление диапазона при получении результата в процентах:
Нижнее значение диапазона: 10,6% – 5,24 п. п. = 5,36%
Верхнее значение диапазона: 10,6% +5,24 п. п. = 15,84%
При расчетах в натуральном выражении, например, результат равен 100 автовладельцам, истина находится в диапазоне от 95 до 105 автовладельцев. Расчет:
Нижнее значение диапазона:
100 автовладельцев – 5,24% = 95 автовладельцев.
Верхнее значение диапазона:
100 автовладельцев +5,24% = 105 автовладельцев.
Большое это расхождение или маленькое? Возможно ли при таком отклонении делать объективные выводы для эффективной работы бизнеса?
В целом, ошибка допустимая. И с полученными данными можно работать. Но! Дальше – интереснее. Сотрудники маркетингового отдела компании Z принимают следующее решение. Так как исследование по региону происходило в определенных населенных пунктах, то почему бы не провести аналитику полученных данных по каждому населенному пункту?
Такое решение принимают без учета того, что ошибку выборки необходимо пересчитывать заново, уже под конкретный населенный пункт.
Например, в городе с населением 250 тыс. человек было опрошено 20 респондентов. Ошибка выборки в данном случае составит уже ± 21,91% (рис. 3).

Что мы получаем в итоге. У нас есть результат исследований: доля потребления антифриза владельцев автомобилей старше 1997 г. в. составляет 10,6%. Вычисляем крайние значения, в которых может находиться истина:
Нижнее значение диапазона:
10,6% – 21,91 п. п. = отрицательное число.
Верхнее значение диапазона:
10,6% +21,91 п. п. = 32,51%
Значит истина находится в диапазоне от 0% до 32,51%.
При такой ошибке не стоит опираться на полученные цифры. Невооруженным взглядом видно, что при такой ошибке использование данных для принятия важных управленческих решений может привести к колоссальной ошибке в бизнесе.
Лучше в этой ситуации принять решение интуитивно. Риски будут те же, зато можно сэкономить деньги и потратить их на что-то более нужное – например, на канцелярию.