Джейд Картер Нейросети. Генерация изображений
Глава 1: Основы генеративных нейронных сетей
Искусственный интеллект (ИИ) и глубокое обучение продолжают стремительно развиваться, открывая новые возможности в обработке данных и решении сложных задач. В рамках глубокого обучения одним из наиболее интригующих направлений стало генеративное моделирование, то есть создание новых данных, которые выглядят так, как будто они были сгенерированы реальными процессами. В этом контексте генеративные нейронные сети (GAN) представляют собой одну из самых инновационных и успешных техник в области генеративного моделирования.
Главная цель генеративных нейронных сетей состоит в создании моделей, способных генерировать новые данные, не существующие в обучающем наборе, но максимально похожие на реальные данные. Такое умение имеет множество практических применений: от создания реалистичных изображений и анимаций до генерации текстов, музыки, 3D-моделей и даже синтеза речи.
Генеративные нейронные сети представляют собой эффективный способ построения вероятностных моделей, которые позволяют моделировать сложные распределения данных. Они являются мощным инструментом для решения таких задач, как генерация контента, улучшение и аугментация данных, исследование данных и обогащение информации.
Идея генеративных нейронных сетей возникла на основе многолетних исследований в области нейронных сетей и глубокого обучения. Однако, история создания GAN охватывает несколько этапов и важных этапов развития, которые привели к их появлению.
Первые шаги в развитии идеи нейронных сетей были сделаны еще в 1940-х годах. Профессор Уоррен МакКаллок и Уолтер Питтс создали модель искусственного нейрона, которая послужила основой для последующих исследований в этой области. В 1950-х и 1960-х годах появились первые искусственные нейронные сети, но они столкнулись с ограничениями в вычислительной мощности и недостатком данных, что привело к их забвению.
В 1986 году профессор Джеффри Хинтон и его коллеги представили метод обратного распространения ошибки, который стал прорывом в обучении глубоких нейронных сетей. Этот метод позволил эффективно обучать сети с множеством слоев, что ранее было затруднительно. Это стало отправной точкой для нового интереса к глубокому обучению.
С начала 2000-х годов интерес к глубокому обучению и нейронным сетям начал стремительно возрастать. Появление более мощных вычислительных ресурсов и больших объемов данных существенно повлияло на возможности обучения сложных моделей. Исследователи стали активно применять нейронные сети в различных областях, таких как компьютерное зрение, обработка естественного языка и распознавание речи, что привело к новым технологическим достижениям.
История создания генеративных нейронных сетей начинается в 2014 году, когда исследователь Иан Гудфеллоу и его коллеги представили статью под названием "Generative Adversarial Networks". В этой статье Гудфеллоу предложил новую архитектуру нейронной сети, основанную на противостоянии двух сетей: генератора и дискриминатора.
Основная идея GAN заключается в противостоянии двух нейронных сетей, которые учатся вместе и улучшают друг друга. Генератор отвечает за создание синтетических данных, пытаясь обмануть дискриминатор, чтобы тот принял сгенерированные данные за реальные. Дискриминатор, в свою очередь, обучается различать реальные данные от сгенерированных. Этот процесс обучения продолжается, пока генератор не станет создавать данные, которые трудно отличить от реальных.
С момента своего появления GAN нашли широкое применение в различных областях, таких как компьютерное зрение, искусственный интеллект, графика, дизайн и другие. Они используются для генерации изображений, аудиофайлов, текстовых данных, создания реалистичных анимаций и многое другое.
Генеративные нейронные сети (GAN) представляют собой инновационный подход к генеративному моделированию данных. Они обещают революционизировать множество областей искусственного интеллекта и принести новые возможности для создания реалистичных и удивительных данных. В следующих главах мы рассмотрим архитектуру и обучение GAN более подробно, а также исследуем их конкретные применения в различных задачах.
Генеративные нейронные сети (GAN) представляют собой инновационный класс искусственных нейронных сетей, которые были впервые представлены в 2014 году исследователем Ианом Гудфеллоу и его коллегами. Они представляют собой мощный подход к генеративному моделированию данных, основанный на противостоянии двух нейронных сетей: генератора и дискриминатора.
Принцип работы GAN основан на соревновательности двух нейронных сетей. Генератор и дискриминатор обучаются вместе и улучшают друг друга в процессе обучения. Генератор отвечает за создание синтетических данных, пытаясь обмануть дискриминатор, чтобы тот принял сгенерированные данные за реальные. Дискриминатор, в свою очередь, обучается различать реальные данные от сгенерированных.
Процесс обучения GAN состоит из нескольких итераций. На каждой итерации генератор создает синтетические данные на основе случайного шума или латентного пространства. Эти данные подаются дискриминатору, который пытается классифицировать их как "реальные" или "сгенерированные". В начале обучения дискриминатор может быть довольно слабым, и его предсказания могут быть неточными. Но по мере обучения дискриминатор улучшает свои классификационные способности и становится все лучше в различении сгенерированных данных от реальных.
С другой стороны, генератор стремится улучшить свои навыки, чтобы создавать данные, которые будут максимально похожи на реальные. Он пытается обмануть дискриминатор, чтобы тот принял сгенерированные данные за реальные. Таким образом, генератор учится создавать данные, которые будут настолько реалистичными, что дискриминатору трудно будет отличить их от реальных данных.
Процесс обучения GAN является итеративным, и сети постоянно совершенствуются в своих способностях. Главная цель заключается в достижении равновесия между генератором и дискриминатором, когда генератор создает данные, которые настолько реалистичны, что дискриминатор не может их отличить от реальных данных.
Применение GAN в генерации изображений является одним из наиболее известных и успешных применений этой технологии. Генеративные нейронные сети могут создавать высококачественные и реалистичные изображения, которые могут быть использованы в различных областях, таких как компьютерное зрение, искусственный интеллект, мультимедиа и дизайн.
Применение GAN в генерации изображений позволяет создавать реалистичные портреты людей, синтезировать фотографии природы или архитектуры, а также анимации и многое другое. Это имеет широкий спектр применений, от развлекательной индустрии и рекламы до медицинского исследования и симуляции. GAN также используются для улучшения разрешения изображений, что может быть полезно в обработке медицинских снимков или улучшении качества видео.
Рассмотрим пример простой реализации GAN для генерации реалистичных изображений с помощью библиотеки TensorFlow и Keras в Python. Этот пример демонстрирует принцип работы GAN на основе простых полносвязных слоев. Он использует набор данных MNIST с рукописными цифрами.
```python
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
# Загрузка данных MNIST
(train_images, _), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28 * 28).astype('float32')
train_images = (train_images – 127.5) / 127.5 # Нормализация данных в диапазоне [-1, 1]
# Гиперпараметры
random_dim = 100
epochs = 10000
batch_size = 128
# Создание генератора
def build_generator():
model = tf.keras.Sequential()
model.add(layers.Dense(256, input_dim=random_dim))
model.add(layers.LeakyReLU(0.2))
model.add(layers.BatchNormalization())
model.add(layers.Dense(512))
model.add(layers.LeakyReLU(0.2))
model.add(layers.BatchNormalization())
model.add(layers.Dense(1024))
model.add(layers.LeakyReLU(0.2))
model.add(layers.BatchNormalization())
model.add(layers.Dense(784, activation='tanh'))
model.add(layers.Reshape((28, 28)))
return model
# Создание дискриминатора
def build_discriminator():
model = tf.keras.Sequential()
model.add(layers.Flatten(input_shape=(28, 28)))
model.add(layers.Dense(1024))
model.add(layers.LeakyReLU(0.2))
model.add(layers.Dense(512))
model.add(layers.LeakyReLU(0.2))
model.add(layers.Dense(256))
model.add(layers.LeakyReLU(0.2))
model.add(layers.Dense(1, activation='sigmoid'))
return model
# Функции потерь и оптимизаторы
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
generator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)
# Создание генератора и дискриминатора
generator = build_generator()
discriminator = build_discriminator()
# Функция обучения GAN
def train_gan():
for epoch in range(epochs):
# Генерация случайных векторов из латентного пространства
noise = np.random.normal(0, 1, size=[batch_size, random_dim])
# Генерация сгенерированных изображений генератором
generated_images = generator(noise)
# Получение случайных реальных изображений из обучающего набора
image_batch = train_images[np.random.randint(0, train_images.shape[0], size=batch_size)]
# Сборка батча из реальных и сгенерированных изображений
X = np.concatenate([image_batch, generated_images])
# Создание векторов меток для реальных и сгенерированных изображений
y_dis = np.zeros(2 * batch_size)
y_dis[:batch_size] = 0.9 # односторонний мягкий ярлык для гладкости
# Обучение дискриминатора на батче
discriminator.trainable = True
d_loss = discriminator.train_on_batch(X, y_dis)
# Обучение генератора
noise = np.random.normal(0, 1, size=[batch_size, random_dim])
y_gen = np.ones(batch_size)
discriminator.trainable = False
g_loss = gan.train_on_batch(noise, y_gen)
if epoch % 100 == 0:
print(f"Epoch: {epoch}, Discriminator Loss: {d_loss}, Generator Loss: {g_loss}")
# Обучение GAN
gan = tf.keras.Sequential([generator, discriminator])
gan.compile(loss='binary_crossentropy', optimizer=generator_optimizer)
train_gan()
```
Код представляет собой простую реализацию генеративной сети (GAN) для генерации реалистичных изображений с использованием библиотек TensorFlow и Keras в Python. Давайте подробно опишем каждую часть кода:
1. Загрузка данных MNIST:
– Загружается набор данных MNIST с рукописными цифрами с помощью функции `tf.keras.datasets.mnist.load_data()`.
– Обучающие изображения сохраняются в переменной `train_images`, а метки классов (которые в данном случае не используются) – в переменной `_`.
– Изображения преобразуются в одномерный формат и нормализуются в диапазоне [-1, 1], чтобы облегчить обучение модели.
2. Определение гиперпараметров:
– `random_dim`: размерность входного шумового вектора (латентного пространства), который будет использоваться для генерации изображений.
– `epochs`: количество эпох обучения GAN.
– `batch_size`: размер батча, используемого для обучения на каждой итерации.
3. Создание генератора (`build_generator`):
– Генератор представляет собой нейронную сеть, которая принимает случайный шум или вектор из латентного пространства и генерирует синтетические изображения.
– В данном примере генератор состоит из полносвязных слоев с функцией активации LeakyReLU и слоями BatchNormalization для стабилизации обучения.
– Финальный слой генератора имеет функцию активации `tanh`, чтобы ограничить значения изображений в диапазоне [-1, 1].
4. Создание дискриминатора (`build_discriminator`):
– Дискриминатор представляет собой нейронную сеть, которая принимает изображения и классифицирует их на "реальные" (1) или "сгенерированные" (0).
– В данном примере дискриминатор также состоит из полносвязных слоев с функцией активации LeakyReLU.
– Финальный слой дискриминатора использует сигмоидную функцию активации для получения вероятности принадлежности изображения к классу "реальные".
5. Определение функций потерь и оптимизаторов:
– В данном примере используется функция потерь бинарной кросс-энтропии (`BinaryCrossentropy`).
– Оптимизаторы для генератора и дискриминатора – `Adam` с заданным коэффициентом обучения.
6. Обучение GAN (`train_gan`):
– На каждой итерации обучения:
– Генерируется случайный вектор шума из латентного пространства.
– Генератор создает синтетические изображения на основе этого шума.
– Из обучающего набора выбирается случайный батч реальных изображений.
– Собирается батч из реальных и сгенерированных изображений.
– Дискриминатор обучается на этом батче с метками "реальные" и "сгенерированные" соответственно.
– Генератор обучается на сгенерированном шуме с метками "реальные".
– Обучение происходит чередованием обучения дискриминатора и генератора, чтобы они соревновались друг с другом.
7. Обучение GAN:
– GAN собирается из генератора и дискриминатора в последовательную модель `gan`.
– Обучение GAN происходит вызовом метода `compile` с функцией потерь `binary_crossentropy` и оптимизатором `generator_optimizer`.
Обучение GAN (Generative Adversarial Network) представляет собой процесс обучения двух компонентов сети: генератора (Generator) и дискриминатора (Discriminator), взаимодействующих друг с другом в конкурентной игре.
Вначале создается последовательная модель GAN, объединяющая генератор и дискриминатор. Это делается путем последовательного объединения слоев генератора и слоев дискриминатора в единую модель. Это позволяет обращаться к генератору и дискриминатору как к единой сущности и проводить общую оптимизацию в процессе обучения.
Для обучения GAN определяется функция потерь (loss function), которая определяет, насколько хорошо работает GAN. В случае GAN, функция потерь использует обычно бинарную кросс-энтропию (binary_crossentropy), которая является распространенным выбором для бинарных классификационных задач.
Также выбирается оптимизатор (optimizer), который отвечает за обновление весов сети в процессе обучения с учетом значения функции потерь. В данном случае, указанный `generator_optimizer` используется для оптимизации параметров генератора.
Обучение GAN происходит чередованием двух основных этапов – обучение генератора и обучение дискриминатора. На каждом этапе происходит подача различных данных и обновление соответствующих параметров моделей. Главная идея заключается в том, что генератор стремится создать реалистичные данные, которые дискриминатор не сможет отличить от реальных, в то время как дискриминатор старается правильно классифицировать как реальные, так и сгенерированные данные.
В процессе обучения GAN происходит динамический баланс между генератором и дискриминатором, и оба компонента учатся улучшать свои навыки в противостоянии друг другу. Целью обучения GAN является достижение равновесия (equilibrium), когда генератор создает реалистичные данные, а дискриминатор неспособен точно отличить сгенерированные данные от реальных.
8. Запуск обучения:
– Обучение GAN происходит путем вызова функции `train_gan`, которая реализует процесс обучения и выводит значения функций потерь на каждой итерации.
Функция `train_gan` в приведенном выше коде выполняет обучение GAN (Generative Adversarial Network) путем последовательного обучения генератора и дискриминатора на заданном наборе данных (dataset) в течение определенного числа эпох (epochs). Здесь предполагается, что у вас уже есть предопределенная архитектура GAN, которая объединяет генератор и дискриминатор в модель `gan`.
Давайте рассмотрим шаги, которые выполняются в функции `train_gan`:
1. Разделение генератора и дискриминатора:
В начале функции, модель GAN разделяется на генератор (Generator) и дискриминатор (Discriminator). Это делается для последующего отдельного обучения каждого из компонентов на различных данных и с разными метками.
2. Цикл по эпохам:
Функция `train_gan` содержит вложенный цикл, который итерируется по заданному числу эпох (epochs). Каждая эпоха представляет собой один полный проход по всему набору данных.
3. Обучение дискриминатора:
Внутри каждой эпохи, первым шагом является обучение дискриминатора. Для этого:
– Генерируются случайные шумовые входы (noise) для генератора.
– Генератор использует эти шумовые входы для создания сгенерированных данных (generated_data).
– Из текущего батча данных (batch) получаются реальные данные (real_data).
– Дискриминатор обучается на реальных и сгенерированных данных, сравнивая их с правильными метками (в данном случае "реальные" и "сгенерированные").
4. Обучение генератора:
После обучения дискриминатора, происходит обучение генератора.
– Генерируются новые шумовые входы для генератора.
– Генератор обучается на шумовых входах с целевыми метками "реальные". Главная цель генератора – создать данные, которые "обманут" дискриминатор, заставив его классифицировать их как "реальные".
5. Вывод результатов:
После каждой эпохи, выводятся значения функции потерь (loss) для генератора и дискриминатора. Это позволяет отслеживать процесс обучения и оценивать, как улучшается производительность GAN с течением времени.
Обратите внимание, что код представляет упрощенную версию обучения GAN и может потребовать дополнительных оптимизаций, регуляризаций и настроек для успешного обучения и достижения стабильного равновесия между генератором и дискриминатором. Точная реализация обучения GAN может различаться в зависимости от архитектуры и задачи, которую вы пытаетесь решить.
В результате выполнения данного кода, GAN будет обучена на наборе данных MNIST и сгенерирует реалистичные изображения рукописных цифр. Обратите внимание, что данная реализация является упрощенной и может быть доработана для повышения качества генерации. Также, для достижения хороших результатов на более сложных данных может потребоваться использование более сложных архитектур и продолжительного обучения на более мощном оборудовании.
Обратите внимание, что это простой пример GAN, и результаты могут быть ограничены. Для достижения более высокого качества генерации, может потребоваться более сложная архитектура с большим количеством слоев и оптимизация параметров. Также, для более сложных данных, например, изображений высокого разрешения, может потребоваться использование более мощных вычислительных ресурсов.
GAN представляют собой важный инструмент в области генеративного моделирования данных, особенно в генерации изображений. Их уникальная архитектура, основанная на противостоянии двух сетей, позволяет создавать высококачественные и реалистичные данные, что открывает новые возможности в различных областях искусственного интеллекта и компьютерного зрения.
Генеративные нейронные сети (GAN) состоят из двух основных компонентов: генератора и дискриминатора. Эти две нейронные сети взаимодействуют и конкурируют между собой в процессе обучения, что приводит к улучшению способности генератора создавать реалистичные данные и дискриминатора различать "реальные" данные от "сгенерированных".
Генератор:
Генератор отвечает за создание синтетических данных, которые должны быть схожи с реальными данными из обучающего набора. Его задача – научиться генерировать изображения, звуки или тексты, которые могут быть внешне неотличимы от реальных данных.
Архитектура генератора зависит от типа данных, с которыми мы работаем. В случае изображений, генератор может состоять из декодеров или сверточных слоев, которые преобразуют входные случайные векторы (шум) из латентного пространства в соответствующие изображения. Каждый слой генератора обрабатывает информацию и постепенно уточняет изображение до получения реалистичного результата.
Важно, чтобы генератор был достаточно сложным и гибким, чтобы адекватно воспроизводить характерные особенности реальных данных, но при этом он не должен быть слишком сложным, чтобы избежать переобучения или нестабильности в обучении.
Дискриминатор:
Дискриминатор представляет собой классификатор, который получает на вход изображения (реальные и сгенерированные) и определяет, является ли каждое изображение реальным или сгенерированным. Его задача – выучить различия между реальными и синтетическими данными.
Для изображений дискриминатор может быть представлен как сверточная нейронная сеть, которая обрабатывает изображение и делает вероятностный вывод о том, насколько оно реально.
Дискриминатор обучается на реальных изображениях из обучающего набора, чтобы распознавать их как "реальные", а затем обучается на сгенерированных изображениях, чтобы распознавать их как "сгенерированные". Этот процесс тренировки учит дискриминатор различать реальные и сгенерированные данные.
Соревнование и обучение GAN:
Главная идея GAN заключается в том, что генератор и дискриминатор соревнуются и улучшают свои навыки в ходе обучения. Генератор старается создавать все более реалистичные данные, чтобы обмануть дискриминатор и заставить его принимать сгенерированные данные за реальные. В свою очередь, дискриминатор старается становиться все лучше в различении реальных и сгенерированных данных.
Процесс обучения GAN основан на чередующихся итерациях. На каждой итерации сначала обучается дискриминатор на реальных и сгенерированных данных, затем обучается генератор на сгенерированных данных. Этот процесс повторяется множество раз до достижения равновесия между генератором и дискриминатором, когда генерируемые данные становятся высокого качества и трудно отличимы от реальных данных.
Архитектуры генератора и дискриминатора являются критическими элементами в успехе GAN. Их оптимальный выбор, оптимизация и тонкая настройка – важные задачи в процессе проектирования GAN для конкретных задач и типов данных. Когда генератор и дискриминатор достигают высокой производительности, GAN могут быть применены в различных областях, таких как генерация изображений, аудио, текста, анимации, улучшение данных и многое другое.
Практически генератор и дискриминатор представляют собой две различные нейронные сети, которые можно реализовать с помощью библиотек для глубокого обучения, таких как TensorFlow и Keras в Python.
1. Генератор:
Вот пример простой архитектуры генератора для генерации изображений с использованием полносвязных слоев:
```python
from tensorflow.keras import layers, models
def build_generator(random_dim, image_shape):
model = models.Sequential()
model.add(layers.Dense(256, input_dim=random_dim))
model.add(layers.LeakyReLU(0.2))
model.add(layers.BatchNormalization())
model.add(layers.Dense(512))
model.add(layers.LeakyReLU(0.2))
model.add(layers.BatchNormalization())
model.add(layers.Dense(1024))
model.add(layers.LeakyReLU(0.2))
model.add(layers.BatchNormalization())
model.add(layers.Dense(np.prod(image_shape), activation='tanh'))
model.add(layers.Reshape(image_shape))
return model
# Пример использования:
random_dim = 100
image_shape = (28, 28, 1)
generator = build_generator(random_dim, image_shape)
```
2. Дискриминатор:
Вот пример простой архитектуры дискриминатора для классификации изображений на "реальные" и "сгенерированные":
```python
def build_discriminator(image_shape):
model = models.Sequential()
model.add(layers.Flatten(input_shape=image_shape))
model.add(layers.Dense(1024))
model.add(layers.LeakyReLU(0.2))
model.add(layers.Dense(512))
model.add(layers.LeakyReLU(0.2))
model.add(layers.Dense(256))
model.add(layers.LeakyReLU(0.2))
model.add(layers.Dense(1, activation='sigmoid'))
return model
# Пример использования:
discriminator = build_discriminator(image_shape)
```
В этом примере генератор представляет собой последовательную модель с несколькими полносвязными слоями и слоями LeakyReLU для добавления нелинейности. Завершается генератор слоем Dense с функцией активации `tanh`, чтобы ограничить значения изображения в диапазоне [-1, 1]. Затем используется слой Reshape, чтобы преобразовать выходные данные в форму изображения.
Дискриминатор также представляет собой последовательную модель с несколькими полносвязными слоями и слоями LeakyReLU. Он принимает изображение в форме, которую ожидает генератор, и выводит вероятность того, что это реальное изображение (значение близкое к 1) или сгенерированное (значение близкое к 0).
Обратите внимание, что это упрощенные примеры архитектур, и для более сложных данных и задач могут потребоваться более глубокие или сложные архитектуры для достижения высокого качества генерации и дискриминации. Также, при работе с изображениями может быть применено сверточные нейронные сети (CNN), которые эффективно работают с пространственными структурами данных.
Основные компоненты GAN: генератор, дискриминатор, функция потерь GAN и оптимизатор. Генератор принимает на вход шумовой вектор и старается создать реалистичные данные, которые дискриминатор будет классифицировать как реальные. Дискриминатор, в свою очередь, принимает на вход реальные и сгенерированные данные, и его задача – отличать между ними. Функция потерь GAN и оптимизатор используются для определения и минимизации ошибки GAN в процессе обучения.
Это представляет упрощенное представление архитектуры GAN. В реальных задачах GAN может быть значительно более сложной с большим числом слоев и компонентов. Кроме того, в реальной реализации могут быть использованы различные слои, функции активации и оптимизаторы в зависимости от конкретной задачи и домена данных.
В контексте нейронных сетей, слой (Layer) представляет собой основную строительную единицу, которая выполняет определенные вычисления и преобразования над данными. Слои объединяют нейроны вместе и формируют структуру нейронной сети, определяя, как данные передаются через сеть и обрабатываются для решения конкретной задачи.
Каждый слой принимает входные данные, выполняет над ними определенные операции, и затем генерирует выходные данные. Каждый нейрон в слое имеет веса (weights) и смещения (biases), которые подстраиваются в процессе обучения для оптимизации производимых вычислений и достижения лучших результатов на задаче.
В GAN (Generative Adversarial Networks) могут быть использованы различные типы слоев, как в генераторе, так и в дискриминаторе. Это зависит от задачи и типа данных, с которыми работает GAN. Ниже перечислены некоторые из наиболее часто используемых слоев для GAN:
1. Сверточные слои (Convolutional Layers):
Сверточные слои (Convolutional Layers) – это основные строительные блоки в архитектурах генеративных нейронных сетей (GAN) для обработки изображений. Они играют ключевую роль в создании генератора для генерации изображений и дискриминатора для классификации изображений на "реальные" и "сгенерированные". Рассмотрим их подробнее:
Сверточные слои работают с пространственными структурами данных, такими как изображения. Вместо того чтобы каждый пиксель рассматривать независимо, они используют небольшие окна (фильтры) для обнаружения локальных паттернов, таких как границы, текстуры или другие визуальные характеристики. Фильтры сверточных слоев применяются к различным областям изображения, чтобы выделить различные признаки.
Первые сверточные слои обычно обнаруживают простые признаки, такие как ребра, углы и текстуры. Последующие слои строят более абстрактные признаки, объединяя меньшие детали в более сложные структуры, такие как объекты и образцы.
Архитектура сверточных слоев включает следующие основные компоненты:
– Фильтры (ядра): это матрицы весов, которые применяются к небольшим окнам входного изображения. Количество фильтров определяет количество выходных каналов в сверточном слое.
– Размер окна (Kernel Size): это размер фильтра, который указывает на его область входного изображения. Часто используются фильтры размером 3x3 или 5x5.
– Шаг (Stride): это параметр, который определяет, насколько далеко перемещается фильтр при применении к изображению. Шаг 1 означает перекрытие, а шаг 2 – нет.
– Заполнение (Padding): это параметр, который позволяет сохранить размеры изображения после свертки. Заполнение добавляет нулевые значения вокруг входного изображения, чтобы убедиться, что фильтр может применяться к пикселям на границах.
Пример использования в GAN:
В генераторе, сверточные слои могут использоваться для увеличения размера скрытых представлений и создания более сложных структур изображений. Они могут быть задействованы в процессе декодирования входного вектора шума из латентного пространства в изображение.
В дискриминаторе, сверточные слои позволяют анализировать изображения и выделять важные признаки, которые помогают отличить реальные данные от сгенерированных.
Современные архитектуры GAN часто используют сверточные слои в различных комбинациях, таких как сверточные нейронные сети (CNN), сверточные автокодировщики (CAE) и условные GAN (cGAN). Эти архитектуры эффективно генерируют изображения, улучшают качество генерации и устойчивы к различным типам данных и задачам.
Сверточные слои являются ключевым инструментом для работы с изображениями в архитектурах GAN и имеют большое значение для успешной генерации и дискриминации данных.
2. Пакетная нормализация (Batch Normalization):
Пакетная нормализация (Batch Normalization) – это техника, применяемая в нейронных сетях, включая генеративные нейронные сети (GAN), для стабилизации обучения и улучшения производительности модели. Она была предложена в 2015 году и стала широко используемым методом для улучшения обучения нейронных сетей.
Основной проблемой, которую решает пакетная нормализация, является "внутренняя ковариация" (internal covariate shift). В процессе обучения распределение активаций слоев может меняться, что приводит к затуханию или взрыванию градиентов и, как следствие, замедлению сходимости модели. Пакетная нормализация решает эту проблему, нормируя активации каждого слоя по мини-пакетам обучающих данных.
Как работает пакетная нормализация:
На каждом шаге обучения пакетная нормализация нормирует активации каждого слоя по мини-пакетам обучающих данных, а не по отдельным примерам. Это помогает уменьшить дисперсию и выравнивает распределение активаций, что содействует стабильности обучения.
Для каждого слоя пакетной нормализации есть два настраиваемых параметра: масштабирование (scaling) и сдвиг (shift). Эти параметры позволяют модели учиться сдвигать и масштабировать нормализованные активации, чтобы сохранить гибкость обучения.
Во время инференса (применения модели на новых данных) параметры пакетной нормализации используются для нормализации активаций, но они могут быть заменены средними значениями и стандартными отклонениями активаций, вычисленными во время обучения.
В GAN, пакетная нормализация может быть применена как в генераторе, так и в дискриминаторе. Ее применение помогает стабилизировать обучение и предотвращает исчезновение или взрывание градиентов, что особенно важно при обучении глубоких моделей GAN.
В генераторе, пакетная нормализация может быть использована вместе с различными слоями, такими как полносвязные слои или сверточные слои. Она позволяет улучшить качество генерации изображений и сделать генератор более устойчивым к различным условиям обучения.
В дискриминаторе, пакетная нормализация помогает улучшить способность модели различать реальные и сгенерированные данные. Это способствует более стабильному и эффективному обучению дискриминатора, что в свою очередь повышает производительность всей системы GAN.
Пакетная нормализация является мощным инструментом для ускорения и улучшения обучения GAN, делая его более стабильным и эффективным для генерации высококачественных данных.
Выравнивающие слои, такие как слои субдискретизации (max pooling или average pooling), используются для уменьшения размерности изображений, что позволяет уменьшить количество параметров и ускорить обучение.
4. Рекуррентные слои (Recurrent Layers):
Рекуррентные слои (Recurrent Layers) – это тип слоев в нейронных сетях, предназначенных для работы с последовательными данными, где каждый элемент последовательности имеет зависимость от предыдущих элементов. Такие данные включают тексты, аудио, временные ряды или видео, где информация упорядочена по времени или последовательности.
Основная особенность рекуррентных слоев заключается в том, что они имеют обратные связи, позволяющие передавать информацию о предыдущих состояниях в текущее. Это позволяет рекуррентным слоям улавливать долгосрочные зависимости в последовательных данных и сохранять контекст информации в течение всего процесса обработки.
Принцип работы рекуррентных слоев:
Рекуррентные слои поддерживают "память состояния" (hidden state), которая представляет собой внутреннее представление слоя на основе предыдущего входа и состояния. Память состояния обновляется на каждом шаге последовательности, что позволяет сохранять контекст информации внутри слоя.
Поток времени – это процесс развертывания рекуррентного слоя на протяжении всей последовательности. Каждый элемент последовательности обрабатывается по очереди, и память состояния обновляется на каждом шаге. Это позволяет обрабатывать последовательности различной длины.
Рекуррентные слои обучаются с использованием метода обратного распространения ошибки. Во время обучения градиенты ошибки распространяются через все шаги развертывания потока времени, что позволяет корректировать параметры слоя таким образом, чтобы модель более эффективно улавливала зависимости в данных.
Применение рекуррентных слоев в GAN:
В GAN, рекуррентные слои могут быть использованы для обработки последовательных данных, таких как тексты или аудио. Например, в GAN для генерации текста, рекуррентный слой может быть использован в генераторе для создания последовательности слов или символов. Рекуррентный генератор может улавливать лингвистические зависимости и структуры текста.
В GAN для аудио или видео, рекуррентные слои также могут использоваться для работы с временными рядами данных. Например, рекуррентный дискриминатор может анализировать последовательности аудиофрагментов или кадров видео, чтобы классифицировать их как реальные или сгенерированные.
Важно отметить, что хотя рекуррентные слои могут эффективно работать с последовательными данными, они также имеют свои ограничения, такие как проблема затухания и взрывания градиентов. В некоторых случаях для обработки последовательностей могут быть предпочтительны другие типы слоев, такие как трансформеры (Transformer Layers), которые представляют собой альтернативную архитектуру, способную эффективно обрабатывать длинные последовательности данных. Выбор определенного типа слоя зависит от конкретной задачи и характеристик данных, с которыми работает GAN.
5. Транспонированные сверточные слои (Transposed Convolutional Layers):
Транспонированные сверточные слои (Transposed Convolutional Layers), также известные как слои деконволюции (Deconvolution Layers), являются важным элементом архитектур генеративных нейронных сетей (GAN), особенно в генераторах. Они позволяют увеличить размер изображения на основе меньших скрытых представлений (функций).
Для лучшего понимания, рассмотрим, как сверточные слои и транспонированные сверточные слои взаимодействуют в GAN:
Сверточные слои, используемые в генераторе GAN, помогают преобразовать входной шумовой вектор из латентного пространства в скрытое представление, которое затем преобразуется в сгенерированное изображение. В сверточных слоях фильтры применяются к небольшим окнам изображения, чтобы выделять различные признаки. Чем глубже сверточные слои, тем более абстрактные признаки они могут извлечь из данных.
После того, как скрытое представление (закодированное изображение) получено в генераторе с помощью сверточных слоев, оно может быть увеличено в размере для создания более крупного изображения. Для этого применяются транспонированные сверточные слои. Эти слои осуществляют обратную операцию сверточных слоев: вместо уменьшения размера изображения, они увеличивают его.
Увеличение размера изображения:
Транспонированные сверточные слои применяются с определенным шагом (stride), что позволяет увеличить размер изображения. Они создают дополнительные пиксели и заполняют пространство между существующими значениями, чтобы получить более крупное изображение.
Расширение латентного пространства:
Увеличение размера изображения с помощью транспонированных сверточных слоев позволяет увеличить сложность генератора и расширить латентное пространство. Это означает, что генератор способен генерировать разнообразные изображения, основываясь на различных комбинациях значений входного шумового вектора.
Использование транспонированных сверточных слоев в других задачах:
Транспонированные сверточные слои не используются только в GAN. Они также широко применяются в других архитектурах глубоких нейронных сетей, таких как сегментация изображений, аннотация видео и другие задачи, где требуется увеличить размер представления данных.
Таким образом, транспонированные сверточные слои являются важным компонентом генераторов GAN, позволяющим увеличить размер изображения и создавать разнообразные и высококачественные сгенерированные данные на основе меньших скрытых представлений.
6. Слои активации (Activation Layers):
Функции активации – это неотъемлемая часть нейронных сетей, включая генеративные нейронные сети (GAN). Они играют ключевую роль в добавлении нелинейности в модель, что позволяет сети учить сложные зависимости в данных и решать более сложные задачи. В GAN функции активации применяются к выходам слоев для того, чтобы вводить нелинейность в генераторе и дискриминаторе, что делает модель более мощной и способной к более сложной генерации и дискриминации данных.
Вот некоторые из самых популярных функций активации, применяемых в GAN:
– ReLU (Rectified Linear Unit):
ReLU функция активации определяется как f(x) = max(0, x). Она заменяет отрицательные значения выхода нейрона на нули и оставляет положительные значения без изменений. Эта функция проста в вычислении и помогает устранить проблему затухания градиентов, которая может возникнуть при использовании других функций активации, таких как сигмоид или тангенс гиперболический.
– LeakyReLU:
LeakyReLU функция активации представляет собой вариант ReLU с небольшим отрицательным наклоном для отрицательных значений. Она определяется как f(x) = max(ax, x), где a – маленькое положительное число, называемое параметром утечки (leak). LeakyReLU помогает избежать проблемы "мертвых нейронов", которая может возникнуть при использовании ReLU.
– Tanh (гиперболический тангенс):
Tanh функция активации определена как f(x) = (e^x – e^(-x)) / (e^x + e^(-x)). Она преобразует значения в диапазон от -1 до 1, что позволяет сети учиться симметричным зависимостям в данных. Tanh также обладает свойством сжатия данных, что может быть полезно при обработке данных со значениями в отрезке [-1, 1].
– Sigmoid:
Sigmoid функция активации определена как f(x) = 1 / (1 + e^(-x)). Она преобразует значения в диапазон от 0 до 1. Ранее sigmoid была часто использована в нейронных сетях, но в настоящее время ее применение ограничено из-за проблемы исчезающего градиента (vanishing gradient problem) при обучении глубоких сетей.
Применение функций активации в GAN:
Функции активации используются в различных слоях генератора и дискриминатора для добавления нелинейности в модель. Они вносят нелинейные преобразования в скрытые представления, что позволяет модели извлекать более сложные признаки из данных. Кроме того, использование функций активации помогает избежать проблем слишком простых или линейных моделей, которые не могут обработать сложные зависимости в данных. Выбор конкретной функции активации зависит от задачи, архитектуры сети и типа данных, с которыми работает GAN. Важно экспериментировать с различными функциями активации и выбрать наилучший вариант для конкретной задачи.
7. Слои потокового обучения (Flatten Layers):
Слои потокового обучения (Flatten Layers) представляют собой важный тип слоев в нейронных сетях, включая генеративные нейронные сети (GAN). Их главная задача – преобразовать выходные данные многомерных слоев в одномерные векторы, чтобы передать эти данные последующим слоям, которые ожидают одномерные входы.
Принцип работы слоев потокового обучения:
– Преобразование многомерных данных:
В процессе обработки данных нейронные сети часто используют сверточные слои (Convolutional Layers) и рекуррентные слои (Recurrent Layers), которые могут выводить данные с различными размерами и формами. Например, после применения сверточных слоев на изображении, выходы могут быть трехмерными тензорами (например, ширина х высота х количество каналов), а после применения рекуррентных слоев на последовательности – двумерными (например, длина последовательности х размерность скрытого состояния).
–Приведение к одномерному вектору:
Чтобы передать данные на последующие слои, которые ожидают одномерные входы, необходимо преобразовать многомерные данные в одномерный вектор. Для этого используются слои потокового обучения (Flatten Layers). Эти слои выполняют операцию "распрямления" данных, преобразуя многомерные массивы в одномерные.
–Исключение пространственной структуры:
Применение слоев потокового обучения исключает пространственную структуру данных. Например, после использования сверточных слоев, которые обычно сохраняют пространственные зависимости в изображениях, слои потокового обучения преобразуют эти зависимости в линейный порядок, что может привести к потере некоторой информации о пространственной структуре.
Применение слоев потокового обучения в GAN:
В GAN, слои потокового обучения применяются, когда данные, обрабатываемые в генераторе или дискриминаторе, имеют многомерную форму, например, после применения сверточных слоев. Слои потокового обучения выполняют роль промежуточного шага в обработке данных перед подачей их на полносвязные слои (Fully Connected Layers) или другие слои с одномерными ожиданиями.
После применения слоев потокового обучения выходные данные становятся одномерными векторами, которые затем передаются на последующие слои для дальнейшей обработки и принятия решений. Это позволяет модели GAN справляться с более сложными задачами, такими как генерация высококачественных изображений или дискриминация между реальными и сгенерированными данными.
8. Полносвязный слой (Fully Connected Layer):
Это один из основных типов слоев в искусственных нейронных сетях. Он также называется слоем с плотными связями (Dense Layer) или линейным слоем (Linear Layer). В полносвязном слое каждый нейрон входного слоя связан с каждым нейроном выходного слоя.
Работа полносвязного слоя заключается в линейной комбинации входных данных с весами и применении функции активации к полученным значениям. Количество нейронов в выходном слое определяет размерность выходных данных. Если полносвязный слой имеет N входных нейронов и M выходных нейронов, то это означает, что каждый из N входных нейронов соединен со всеми M выходными нейронами.
Математически, для полносвязного слоя можно представить следующим образом:
```
y = activation(W * x + b)
```
где:
– `x` – входные данные (вектор признаков)
– `W` – матрица весов размерности (N, M), где N – количество входных нейронов, а M – количество выходных нейронов
– `b` – вектор смещений (bias) размерности (M)
– `activation` – функция активации, которая применяется к линейной комбинации входов с весами и смещениями
– `y` – выходные данные (результат работы слоя)
Полносвязные слои обладают большой гибкостью и способны учить сложные нелинейные зависимости в данных. Они широко используются в различных архитектурах нейронных сетей, включая обычные многослойные перцептроны, сверточные нейронные сети, рекуррентные нейронные сети и другие.
В контексте генеративных нейронных сетей (GAN), полносвязные слои могут использоваться как часть архитектур генератора и дискриминатора для обработки данных и создания синтетических или классификации реальных и сгенерированных данных. Они являются основными строительными блоками в многих GAN-архитектурах.
Это только небольшой набор типов слоев, которые можно использовать в архитектурах GAN. В реальности GAN могут быть более сложными и включать комбинации различных типов слоев, а также другие дополнительные слои и техники, такие как слои с разреженной активацией, слои dropout, слои батч-нормализации с применением нормализации по статистике обучающего набора (Instance Normalization) и другие. Архитектуры GAN часто являются предметом исследований и экспериментов для достижения наилучшего качества генерации и дискриминации в зависимости от конкретной задачи.
Для удобства понимания приведем таблицу, которая содержит типы слоем и их примеение в GAN: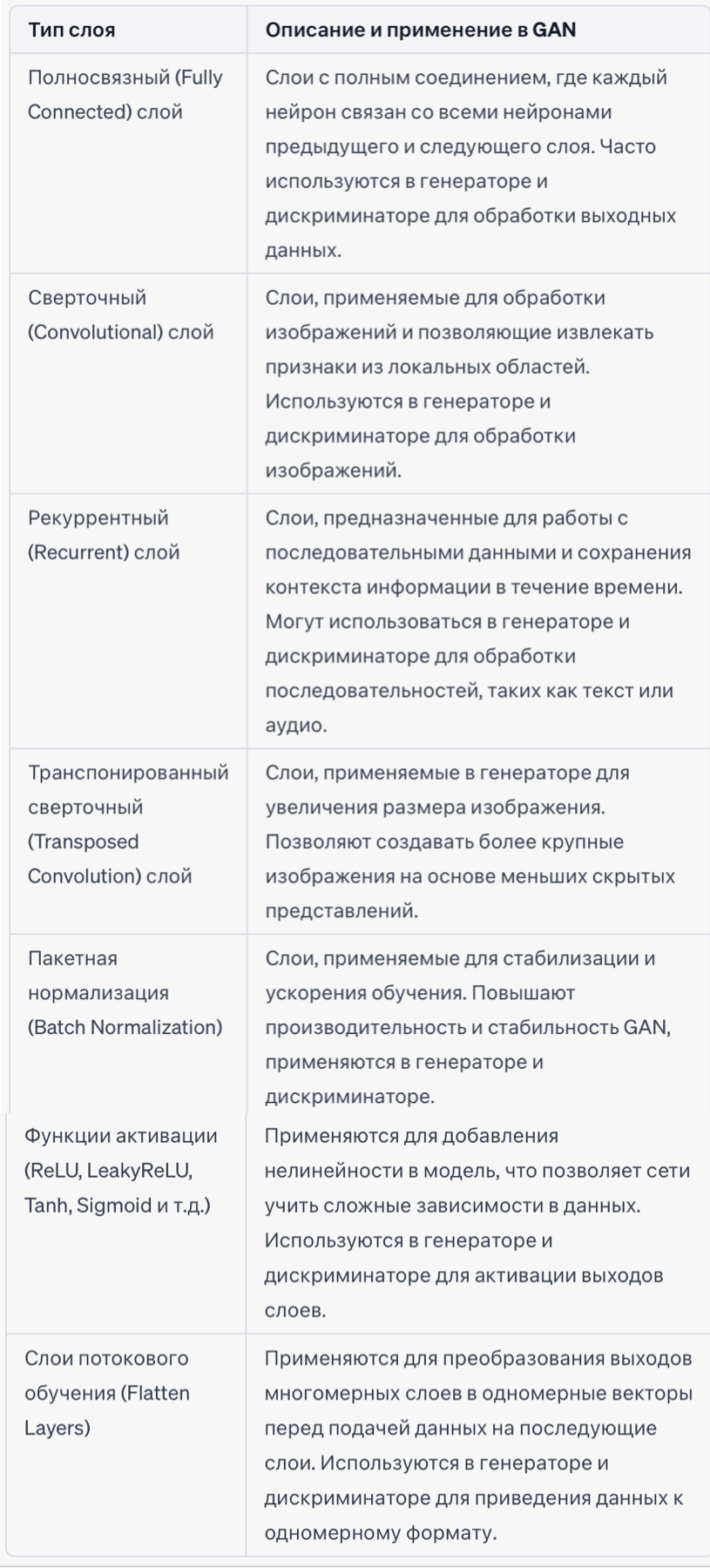
Приведенная таблица не является исчерпывающим списком всех возможных слоев и их применения в генеративных нейронных сетях (GAN). Архитектуры GAN могут быть очень разнообразными и креативными, и различные задачи могут потребовать различных комбинаций слоев для достижения оптимальных результатов.
Для каждой конкретной задачи или типа данных, с которыми работает GAN, могут быть разработаны уникальные архитектуры, использующие сочетания различных слоев для наилучшего выполнения поставленной задачи. От выбора слоев и их гиперпараметров зависит успешность обучения и качество генерируемых данных.
Помимо уже упомянутых слоев, существуют и другие типы слоев, которые можно использовать в GAN в зависимости от контекста:
– Условные слои: позволяют управлять генерацией данных путем добавления дополнительной информации в виде условий. Это может быть полезно, например, для задач стилизации или модификации изображений.
– Трансформеры (Transformer Layers): представляют собой альтернативную архитектуру для работы с последовательными данными, такими как тексты или временные ряды.
– Residual Blocks: используются в генераторе для создания более глубоких сетей, помогая избежать проблемы затухания градиентов и улучшая процесс обучения.
– Дополнительные слои нормализации: такие как Instance Normalization, Layer Normalization и другие, которые могут быть применены для стабилизации и нормализации данных.
– Слои внимания (Attention Layers): позволяют сети фокусироваться на определенных участках данных и улавливать более важные информационные паттерны.
Архитектура GAN является творческим процессом, и часто оптимальные решения могут быть найдены только через эксперименты и исследования. Разработчики и исследователи должны аккуратно подбирать слои и их параметры, учитывая особенности конкретной задачи и типа данных.
Ориентирование в различных типах слоев нейронных сетей может быть сложной задачей, особенно для начинающих. Шпаргалки – это полезные и компактные ресурсы, которые помогают быстро вспомнить основные характеристики каждого слоя и их применение. Ниже представлены примеры удобных шпаргалок для ориентирования в слоях нейронных сетей:
Шпаргалка по сверточным слоям (Convolutional Layers)
2. Шпаргалка по рекуррентным слоям (Recurrent Layers):
3. Шпаргалка по полносвязным слоям (Fully Connected Layers):
Это примеры исходя из наиболее популярных слоев. Помните, что существует множество других типов слоев и их вариантов, которые могут быть использованы для различных задач и в разных архитектурах нейронных сетей. При работе с GAN и другими нейронными сетями, рекомендуется глубже изучить каждый тип слоя и экспериментировать с их комбинациями для оптимизации вашей конкретной задачи.